GPT 5.4 : un grand pas pour Codex
Je suis un peu en retard pour cette revue de modèle, mais cela m'a donné plus de temps pour réfléchir aux axes qui comptent pour les agents. Les benchmarks traditionnels réduisent la performance des modèles à un score unique de justesse – ils l'ont toujours fait parce que c'était simple, facile à utiliser rapidement pour évaluer la performance, etc. C'est également un conseil que je donne aux personnes essayant de construire de bons benchmarks : il doit se réduire à un chiffre interprétable. Cela sera probablement toujours vrai dans un an ou deux, et les benchmarks pour les agents seront meilleurs, mais pour le moment, cela ne correspond pas vraiment à ce que nous ressentons, car les tâches agentiques reposent sur un mélange de justesse, de facilité d'utilisation, de rapidité et de coût. Finalement, les benchmarks aborderont individuellement ces aspects.
Là où GPT 5.4 semble être un autre modèle incrémental sur certains benchmarks théoriques, en pratique, il représente un pas significatif dans ces quatre traits. GPT 5.4 dans Codex, toujours en mode rapide et avec un effort élevé ou très élevé, est le premier agent d'OpenAI qui semble capable de réaliser de nombreuses tâches aléatoires que l'on peut lui confier.
Je n'ai pas été particulièrement impliqué dans l'ingénierie logicielle ces derniers mois, donc la plupart de mes travaux avec des agents ont été des projets plus petits (pas totalement uniques, mais suffisamment petits pour que j'aie construit l'ensemble et géré la conception sur plusieurs semaines), des analyses de données et des tâches de recherche. Lorsque vous adoptez un style de travail natif aux agents, cela implique beaucoup d'APIs régulières, de packages en arrière-plan (comme l'installation et la gestion de binaires LateX, ffmpeg, outils de conversion multimédia, etc.), des opérations git, la gestion de fichiers, la recherche, etc. Avant GPT 5.4, je me détachais toujours des agents d'OpenAI à cause d'une accumulation de petites frustrations. Cela ressemblait à des abandons en colère. J'avais l'impression de m'approcher de GPT 5.2 Codex, mais il échouait sur une opération git et je devais le réinitialiser. Ces difficultés ne sont plus présentes.
L'autre changement subtil dans l'approche de GPT 5.4 – la principale raison pour laquelle je pense qu'OpenAI est de retour dans la guerre des agents – est que cela semble tout simplement un peu plus "juste". Je classe cela différemment des tâches routinières que j'ai évoquées ci-dessus, et cela concerne la manière dont le produit (c'est-à-dire le modèle) présente les sorties, les requêtes, et tout cela à l'utilisateur. Cela a à voir avec la facilité d'accès. C'est toujours la plus grande force de Claude dans sa croissance astronomique. Non seulement Claude a été immensément utile, mais il possède un charme et une valeur divertissante qui incitent les nouveaux utilisateurs à rester. GPT 5.4 a un peu de cela, mais les forces sous-jacentes du modèle de Claude lui donnent encore une impression de chaleur.
Là où Claude est un modèle super intelligent, avec du caractère, une tournure de phrase dans un débat, et parfois une petite oublie, les modèles d'OpenAI dans Codex semblent méticuleux, légèrement froids, mais profondément mécaniques. J'utiliserais Claude pour des choses sur lesquelles j'ai besoin de plus d'opinion et GPT 5.4 pour traiter une liste de tâches extrêmement spécifique. Le suivi des instructions de GPT 5.4 est si précis que je dois apprendre à interagir avec les modèles différemment après avoir passé tant de temps avec Claude. Claude, dans certains domaines, se révèle être un excellent modèle pour votre intention. GPT 5.4 fait simplement ce que vous lui demandez. Ce sont des philosophies très différentes de "ce qui fera le meilleur modèle pour un agent", Claude attirera probablement les nouveaux venus, mais GPT 5.4 séduira probablement le coordinateur d'agents expérimenté qui souhaite libérer son armée d'IA sur des tâches distribuées.
En dehors du charme, et oserais-je dire du goût, de nombreux facteurs d'utilisabilité sont en réalité meilleurs du côté d'OpenAI. L'application Codex est convaincante – je ne l'utilise pas toujours, mais parfois je l'adore totalement. Je soupçonne qu'une innovation substantielle est à venir sur l'apparence de ces applications. Personnellement, je m'attends à ce qu'elles finissent par ressembler à Slack (lorsque plusieurs agents doivent communiquer entre eux, sous ma supervision).
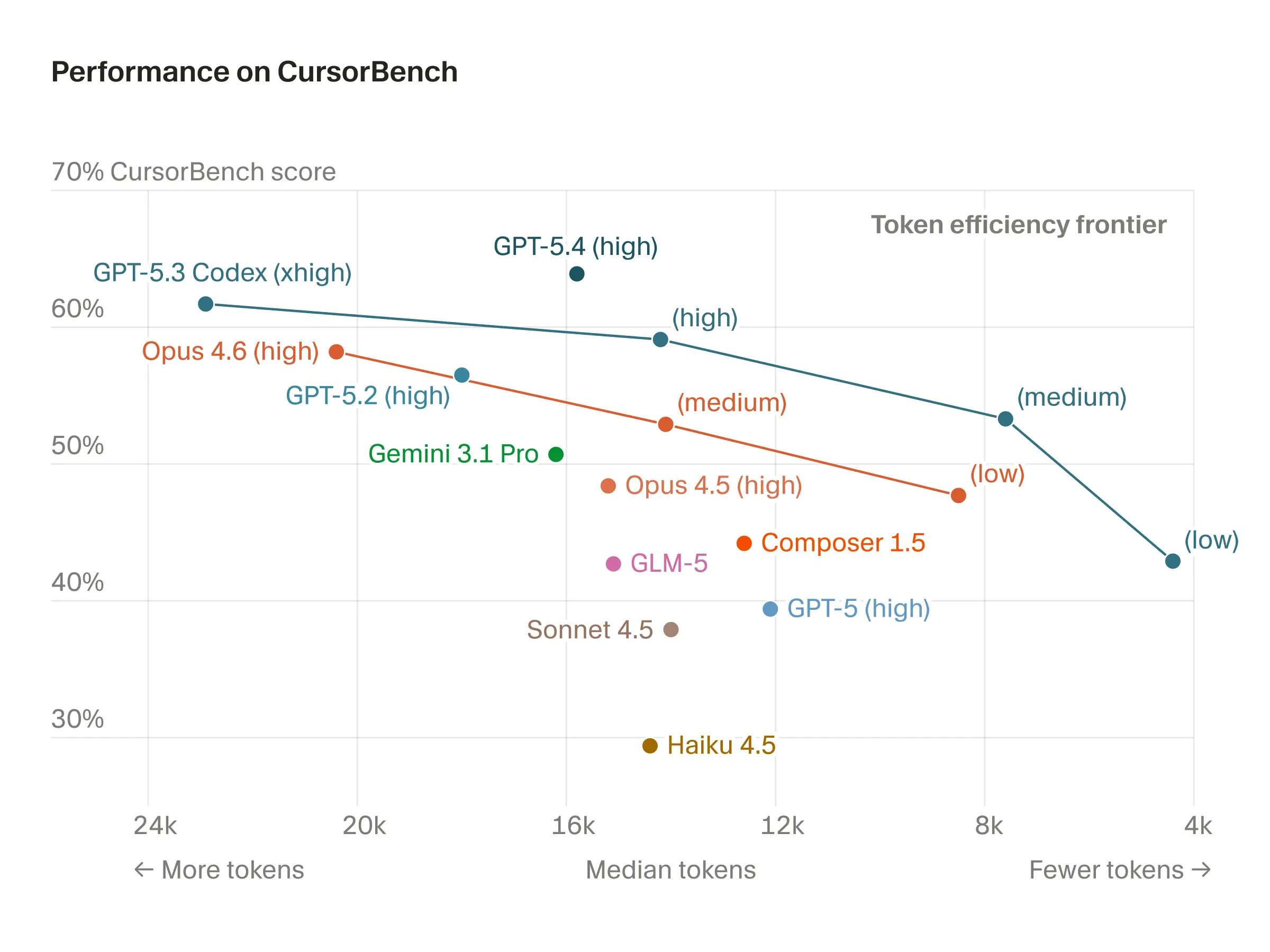
OpenAI propose également nativement un mode rapide pour ses modèles avec un abonnement et des limites de taux très élevées. Je suis sur le plan Claude à 100 $/mois et le plan ChatGPT à 200 $/mois depuis un certain temps. Je n'ai jamais été proche de mes limites Codex avec le mode rapide et un effort de raisonnement très élevé, alors que j'atteins mes limites avec Claude de temps en temps. Il y a définitivement une raison modélisante à cela – la plupart des blogs de sortie d'OpenAI montrent chaque modèle itératif étant substantiellement plus concis en termes de nombre de tokens nécessaires pour atteindre une performance optimale sur les benchmarks. C'est une mesure de l'efficacité du raisonnement. Cette image de benchmark en 2D (ou plus) est exactement la direction que prend le monde.
Voici un graphique de Cursor, qui, malheureusement, n'inclut pas tous les efforts de raisonnement de GPT 5.4, mais qui confirme ce point dans une évaluation tierce. Ce qui manque à travers les familles de modèles, c'est la vitesse et le prix (un proxy pour le calcul total utilisé) pour y parvenir.
Le dernier avantage de GPT 5.4, et des modèles agentiques d'OpenAI en général, est une gestion du contexte bien meilleure. En les utilisant régulièrement maintenant, j'ai l'impression de n'avoir jamais atteint le mur du contexte ou le point d'anxiété contextuelle. L'efficacité du raisonnement, je le soupçonne, permet au modèle de faire beaucoup plus avec sa fenêtre de contexte initialement vide. Ensuite, lorsque GPT 5.4 se compacte, cela est moins perceptible.
Le seul problème que j'ai rencontré avec Claude Opus 4.6 et GPT 5.4 est une légère oublie. Si vous donnez aux modèles plusieurs tâches dans un seul message en dehors du mode de planification, je constate qu'ils ont souvent tendance à les oublier. Parfois, cela donne l'impression que les modèles bugent et essaient de résoudre un problème précédent plutôt que les plus récents. Je ne suis pas sûr de la cause exacte dans le modèle ou le cadre, mais parfois j'aime préparer quelques messages en voyant le modèle travailler sur quelque chose, pour affiner la tâche, mais actuellement cela tend à être un résultat assez risqué, sauf dans les cas d'utilisation les plus simples.
Ces jours-ci, j'utilise à la fois GPT et Claude de manière extensive, principalement en fonction de mon humeur, et j'ai accompli plus que jamais. Avoir une intégration GPT 5.4 Pro directement avec Codex, par exemple comme \ultrathink, serait un grand différenciateur pour OpenAI. Ces modèles ont été incroyables.
Dans l'ensemble, je considère GPT 5.4 comme un modèle agentique qui apporte beaucoup plus de simplicité d'utilisation et d' "agentitude" à la très solide base logicielle de GPT 5.3 Codex. C'est un grand pas, et je suis incroyablement excité de voir laquelle de ces deux entreprises publiera une mise à jour en premier. Sur le papier, énumérer les forces de GPT 5.4 en termes de meilleure performance de codage, de meilleure vitesse, de meilleure gestion du contexte, de meilleures limites de taux, témoigne de la complexité du choix d'un modèle. J'apprécie encore un peu plus Claude pour des raisons qui ne figureront jamais dans les benchmarks. Cela me pousse à taper "claude" dans mon terminal au début de ma journée, plutôt que "codex".