Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Ingénierie des caractéristiques avec des LLM : Techniques et exemples en Python
Qu'est-ce que l'ingénierie des caractéristiques avec des LLM ?
L'ingénierie des caractéristiques avec des LLM (Large Language Models) représente une avancée significative dans le domaine de l'apprentissage automatique. En exploitant ces modèles de langage de grande taille, les ingénieurs peuvent transformer des données brutes en caractéristiques d'entrée structurées, optimisant ainsi les performances des systèmes d'apprentissage. Contrairement aux méthodes traditionnelles qui reposent sur des transformations manuelles, les LLM permettent d'extraire des signaux sémantiques et structurés, enrichissant les modèles avec des informations contextuelles.
Cette nouvelle approche permet aux ingénieurs de développer des modèles d'apprentissage automatique par différentes méthodes, incluant à la fois des transformations numériques et des représentations basées sur le contexte. Les modèles de langage pré-entraînés sont utilisés pour transformer des entrées brutes en représentations structurées de haute dimension, ce qui aide les modèles à obtenir de meilleures performances. Les modèles utilisent le contexte pour déterminer les relations entre les éléments tout en créant des caractéristiques qui expriment un sens au-delà des simples motifs statistiques.
Comment cela diffère-t-il de l'ingénierie des caractéristiques traditionnelle ?
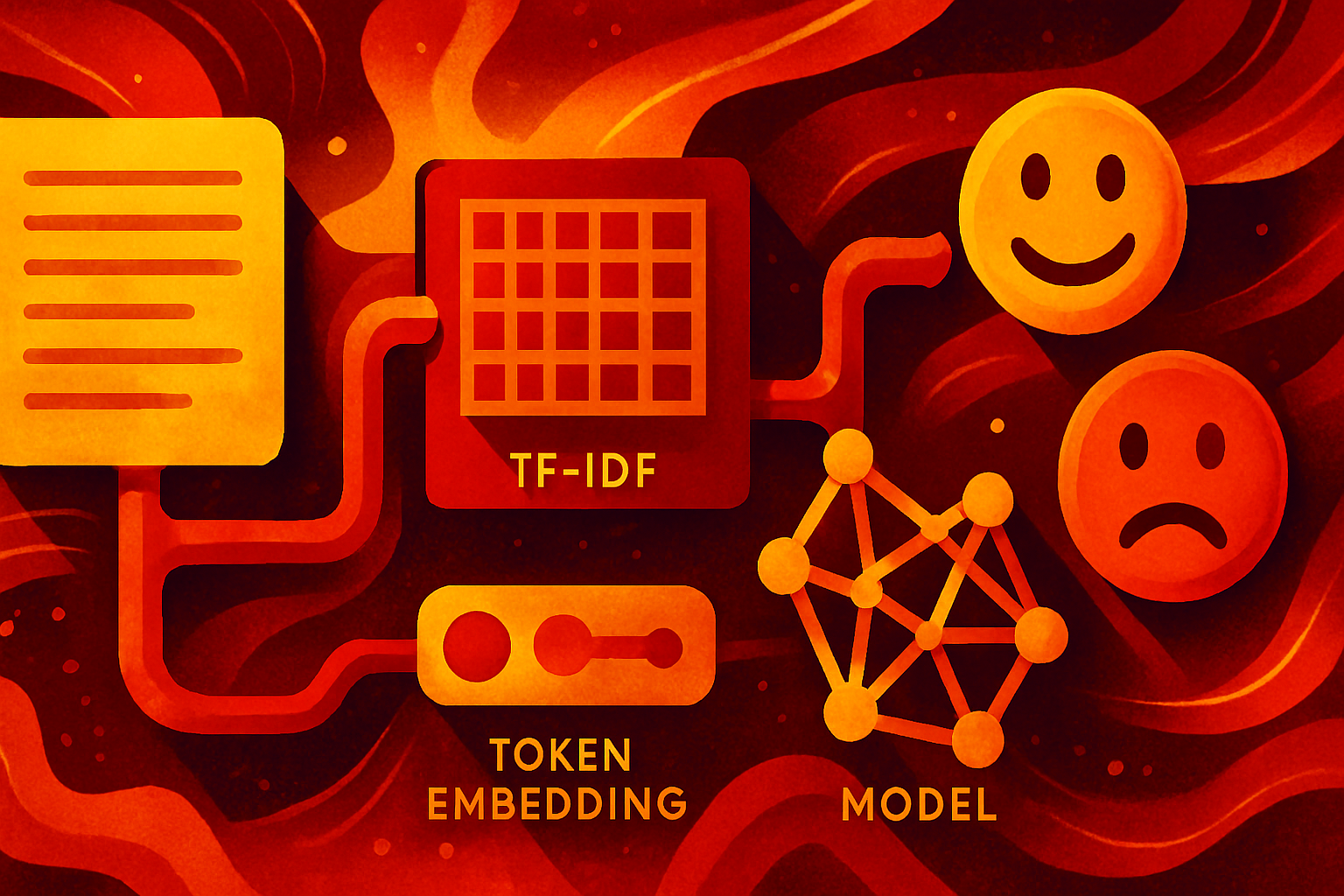
L'ingénierie des caractéristiques traditionnelle s'appuie sur des règles et des transformations manuelles pour créer des caractéristiques. En revanche, les LLM capturent le sens et les intentions des utilisateurs, ainsi que les relations entre les données, souvent manquées par l'encodage manuel. Les méthodes traditionnelles, comme TF-IDF, traitent les mots comme des entités séparées, perdant ainsi les relations et les significations émotionnelles. Les LLM, en revanche, utilisent leur formation sur de vastes bases de données textuelles pour comprendre le contexte linguistique et extraire des caractéristiques sémantiques.
La transition : des caractéristiques manuelles aux caractéristiques sémantiques
L'apprentissage automatique développe des modèles grâce à l'utilisation de caractéristiques fabriquées à la main, qui incluent des vecteurs one-hot et des valeurs numériques standardisées. Les caractéristiques manuelles présentent des restrictions car elles ne prennent pas en compte le contexte et nécessitent des connaissances spécialisées, tout en ne gérant pas les différences subtiles. La méthode TF-IDF traite les mots comme des entités séparées, ce qui entraîne une perte des relations entre les mots et de leur signification émotionnelle.
Les limitations des méthodes traditionnelles incluent la nécessité de connexions permanentes au système et une expertise spécifique au domaine. Le système échoue à inclure à la fois des connaissances générales et des connexions complexes. Un modèle de sac de mots nécessite plus de connaissances que simplement "nourriture froide" pour reconnaître des sentiments négatifs. Les ressources humaines doivent passer beaucoup de temps à identifier toutes les situations exceptionnelles.
Les LLM fonctionnent dans leurs contextes respectifs en utilisant leur formation à partir de vastes bases de données textuelles pour acquérir des connaissances et reconnaître des motifs. Le système comprend le contexte linguistique grâce à leur présence de connaissances du monde et leur capacité à comprendre des messages cachés. Le système extrait des caractéristiques sémantiques à partir des données via les LLM, qui créent des caractéristiques automatiques identifiant des éléments de données tels que le sentiment, le sujet et les catégories de risque.
L'importance de cette transition réside dans sa capacité à démontrer que les caractéristiques sémantiques offrent de meilleurs résultats que les caractéristiques créées par l'homme lorsqu'il s'agit de tâches complexes. Le système nécessite moins d'heuristiques de caractéristiques pour ses opérations, ce qui se traduit par des processus de test plus rapides.
Techniques clés en ingénierie des caractéristiques avec des LLM
Cette section illustrera les méthodes clés avec des exemples de code. Nous générons de petites données d'échantillon et montrons comment les caractéristiques sont dérivées.
Embeddings comme caractéristiques
Les LLM produisent des vecteurs sémantiques denses à partir de texte. Les embeddings extraits fonctionnent comme des caractéristiques numériques qui permettent au modèle de comprendre un sens qui dépasse les simples fréquences de mots. Nous pouvons utiliser un modèle de transformateur pour créer des embeddings de phrases de 384 dimensions via l'encodage de phrases.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["J'aime l'apprentissage automatique", "Le film était fantastique"]
embeddings = model.encode(sentences)
print("Forme des embeddings :", embeddings.shape)
La forme de sortie (2, 384) montre que deux phrases sont mappées en vecteurs denses de 384 dimensions (un par phrase). Les vecteurs représentent des propriétés sémantiques du texte, incluant des significations connexes et des expressions émotionnelles.
Quand utiliser des embeddings vs des caractéristiques traditionnelles :
from sklearn.feature_extraction.text import TfidfVectorizer
docs = [
"Le chat est assis sur le tapis",
"Le chien a mangé le chat",
]
# TF-IDF traditionnel : sac de mots clairsemé
tfidf = TfidfVectorizer()
X_tfidf = tfidf.fit_transform(docs)
# Embeddings LLM : caractéristiques sémantiques denses
X_emb = model.encode(docs)
print("Forme des caractéristiques TF-IDF :", X_tfidf.shape)
print("Forme des caractéristiques d'embeddings LLM :", X_emb.shape)
La forme des caractéristiques TF-IDF crée une matrice clairsemée de (2×6) contenant six termes uniques, tandis que les embeddings LLM existent sous forme de vecteurs denses de (2×384). Les embeddings présentent le sens des mots dans leur contexte car ils montrent comment les synonymes se rapportent les uns aux autres, par exemple "chat" et "chien". Utilisez des caractéristiques sémantiques provenant des embeddings, tandis que les caractéristiques traditionnelles fonctionnent pour des données numériques simples et des données catégorielles à haute fréquence nécessitant un encodage clairsemé.
Extraction de caractéristiques basée sur des prompts
Nous pouvons inciter le LLM à extraire des informations structurées spécifiques à partir du texte. Les sorties du modèle peuvent être analysées en caractéristiques.
from transformers import pipeline
extractor = pipeline("text2text-generation", model="google/flan-t5-base")
# Exemple de texte
text = "La batterie du téléphone dure toute la journée et la performance est fluide"
result = extractor(prompt, max_length=50)
print(result[0]["generated_text"])
Nous utilisons le prompt LLM qui indique "Extraire le sentiment (positif/négatif), le problème du produit et la performance de cet avis." Le modèle retourne des caractéristiques structurées sous forme de dictionnaire similaire à JSON. Les caractéristiques de sentiment, de sujet et d'urgence existent désormais comme des colonnes séparées que nous pouvons intégrer dans notre système de classification.
Extraction guidée par schéma
Un schéma JSON peut être appliqué lors d'une invocation afin d'assurer des sorties cohérentes. Par exemple :
# Extraire au format JSON
result = extractor(prompt, max_length=100)
print(result[0]["generated_text"])
Génération de caractéristiques sémantiques
Les LLM génèrent de nouveaux attributs descriptifs qui peuvent être appliqués à la fois à des lignes uniques et à des valeurs de données individuelles.
{"avis": "Qualité de caméra géniale mais la batterie se décharge rapidement"},
{"avis": "Abordable et durable, bon pour un usage quotidien"}
Générer une nouvelle caractéristique appelée 'user_intent' à partir de cet avis :
result = extractor(prompt, max_length=50)
print(result[0]["generated_text"])
Le LLM extrait l'intention de l'utilisateur à partir de l'avis grâce à son analyse du texte. Le système transforme le texte brut en caractéristiques structurées qui montrent la préférence de l'utilisateur pour les caméras et leur préoccupation concernant la durée de vie de la batterie. Le système permet aux utilisateurs d'ajouter de nouvelles colonnes qui améliorent la compréhension du modèle des motifs d'activité des utilisateurs.
Création de caractéristiques contextuelles
Les LLM peuvent générer des caractéristiques textuelles lorsqu'ils utilisent leurs connaissances pour analyser la valeur d'une caractéristique dans des situations spécifiques. Le LLM utilise des informations de code postal pour expliquer la zone géographique correspondante.
result = extractor(prompt, max_length=50)
print(result[0]['generated_text'])
Le LLM utilise les informations des avis des clients pour déterminer à quel groupe de clients appartient le critique. Le système transforme le texte d'entrée en une étiquette normalisée qui affiche les deux principales préférences de l'utilisateur pour des produits abordables et durables. Le système permet aux utilisateurs de mettre en œuvre une nouvelle caractéristique qui permet aux modèles de catégoriser les utilisateurs selon leurs motifs comportementaux et leurs préférences spécifiques.
Espaces de caractéristiques hybrides (pipelines multimodaux)
Les pipelines multimodaux combinent différentes sources de données pour enrichir les caractéristiques extraites, offrant ainsi une vue plus complète et précise des données analysées.