FAISS and BM25: Revolutionizing the Hybrid RAG System
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
The rapid evolution of large language models and vector embeddings has propelled retrieval-augmented generation (RAG) to the forefront of solutions for querying unstructured documents. This process, which seems almost magical, allows users to upload a document, ask a question, and receive a relevant answer. However, this apparent magic conceals an underlying complexity: information retrieval. Often, it is not the language model itself that fails, but rather the data retrieval step.
Dense vector search is a powerful method for identifying semantically similar texts. It can understand that terms like "urban spending" and "city spending" are equivalent. However, it can falter when it comes to retrieving precise information such as an error code, a contract clause number, or a specific financial figure, sometimes returning incorrect results with high confidence. In contrast, keyword search, such as BM25, excels at exact matching but lacks semantic understanding. For it, "automobile" and "car" are distinct entities, and a rephrased question may leave it perplexed.
The reality is that neither dense vector search nor keyword search is universally superior. Each has its strengths in specific types of queries. In complex documents like legal contracts, financial reports, or technical manuals, both approaches are necessary. The hybrid RAG system addresses this need by using both retrieval methods simultaneously and merging their results through reciprocal rank fusion (RRF). This allows for the combination of the semantic understanding of vector search with the precision of keyword search, all with minimal additional cost.
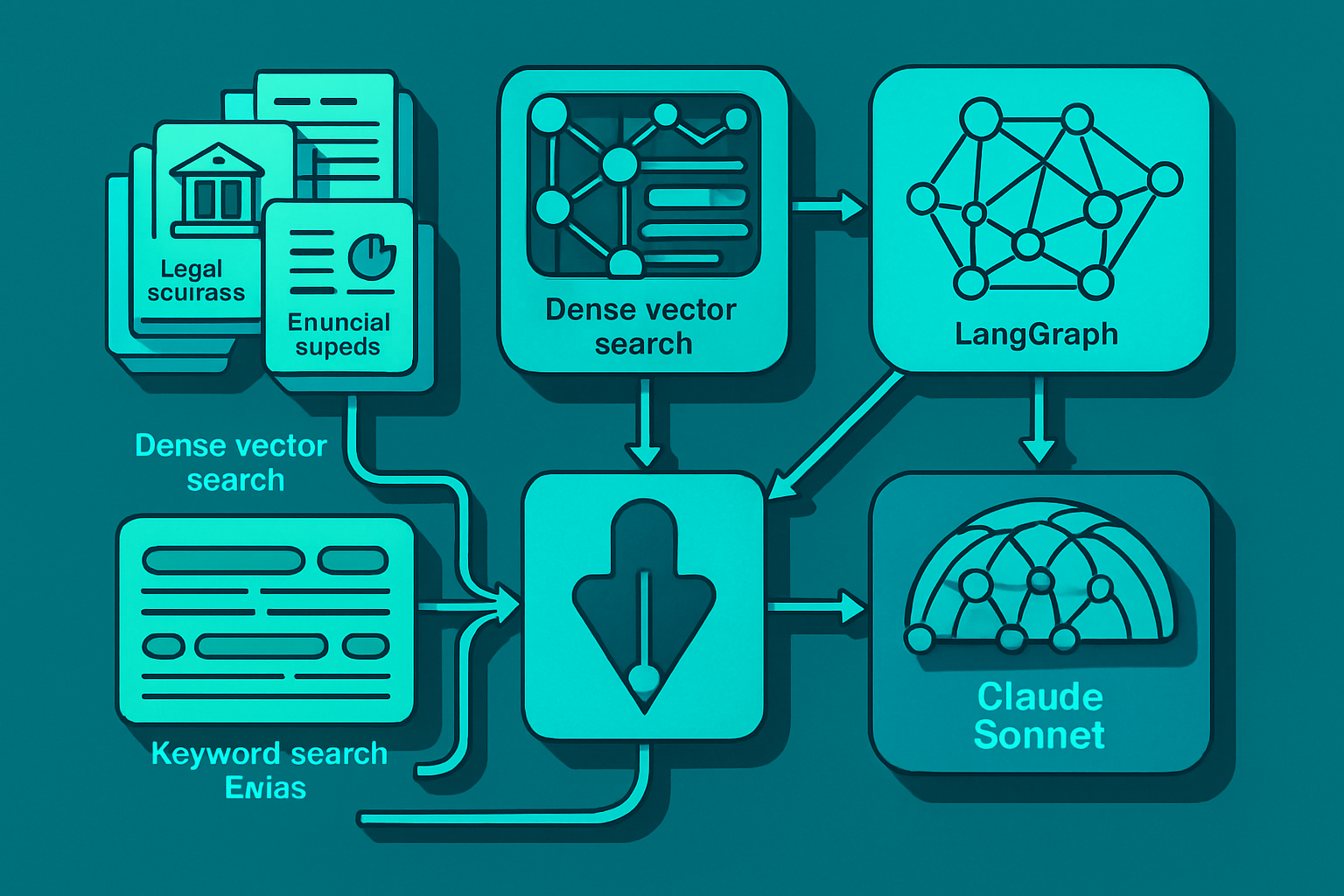
In this article, we will explore the construction of a complete hybrid RAG system. We will use FAISS for dense search, BM25 for keyword search, and reciprocal rank fusion to combine the results into a single, better-ranked list. LangGraph will orchestrate everything, while a Streamlit user interface will allow users to switch between retrieval modes and examine each item and score behind each response.
Real-World Use Cases
This hybrid system offers effective solutions for several concrete use cases:
- Legal teams can query contracts to find both specific clause numbers (exact match) and understand the underlying intent (semantic).
- Financial analysts can ask questions about definitions like EBITDA and obtain quarterly revenue figures from earnings reports.
- Support engineers can search for error codes in technical manuals while asking questions about the root causes of issues.
- Research teams can query dozens of articles to obtain both exact citations and conceptual similarities.
The complete code for this system is available on GitHub: agentic-ai-usecases/beginner/hybrid-rag.
The Single-Mode Retrieval Problem
Before diving into the code, it is essential to understand why hybrid retrieval is crucial.
Dense vector search transforms text into high-dimensional embeddings and identifies the nearest neighbors by cosine similarity. It excels at handling paraphrases: a question like "What is the profit margin rate?" can find answers such as "net income as a percentage of revenue," even if no words overlap with the initial query. However, it may miss important elements like ERR_4021 if this token is rare in the training data and lies in a sparsely populated region of the embedding space.
BM25, on the other hand, is a classic information retrieval algorithm that relies on term frequency and inverse document frequency. It evaluates documents based on the number of query words present and the rarity of those words across the entire corpus. It is effective for finding exact matches, part numbers, named entities, and specific terminologies. Its weakness lies in its lack of semantic understanding, which means that terms like "automobile" and "car" are perceived as entirely distinct.
Hybrid Retrieval
Hybrid retrieval combines these two approaches. The merged ranked list highlights items that are both semantically and lexically relevant, which is ideal when the document contains a mix of technical terms and descriptive prose.
RRF (Reciprocal Rank Fusion)
The crucial question is how to prioritize the items. The answer lies in RRF.
RRF is a ranking fusion algorithm that combines multiple ranked lists into a single unified ranking, without regard for the raw score values of each individual retriever. Rather than asking "which item received the best overall score?", it asks "which item appeared near the top of the most lists?".
RRF Steps
The formula is simple:
RRF score(d) = Σ 1 / (k + rank(d, list))
where k is a smoothing constant (typically 60) and rank(d, list) is the indexed position at 1 of item d in the results list of a given retriever. The sum is performed over each retriever that returned the item.
RRF Properties
Several properties make RRF particularly suitable for hybrid retrieval:
-
Independence of score scale: FAISS's cosine similarity ranges from [-1, 1], while BM25 scores are unbounded and depend on document length. These two numbers are not comparable, and RRF circumvents this issue by first converting everything into ranks.
-
Rewards inter-list agreement: An item that ranks 1st in BM25 and 2nd in vector search receives a higher score than an item that ranks 1st in only one list. The fusion step amplifies agreement, which is exactly the signal sought.
-
Robustness to outliers: A single retriever that confidently returns a wrong item at rank 1 can contribute only 1 / (60 + 1) ≈ 0.016 to the RRF score. If the other retriever did not return this item at all, it does not get close to the top. In practice, this means that when both retrievers agree on an item, it rises to the top. When only one retriever highlights it, it still receives credit but not enough to dominate if another item had broader support.
System Architecture
Here is the complete architecture of what we are going to build:
Note on Architecture: A key design decision is the joint use of FAISS and BM25 to maximize the accuracy and relevance of search results.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.