La recherche en IA te passionne ?
Les papers et avancées qui comptent, expliqués simplement, chaque soir. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
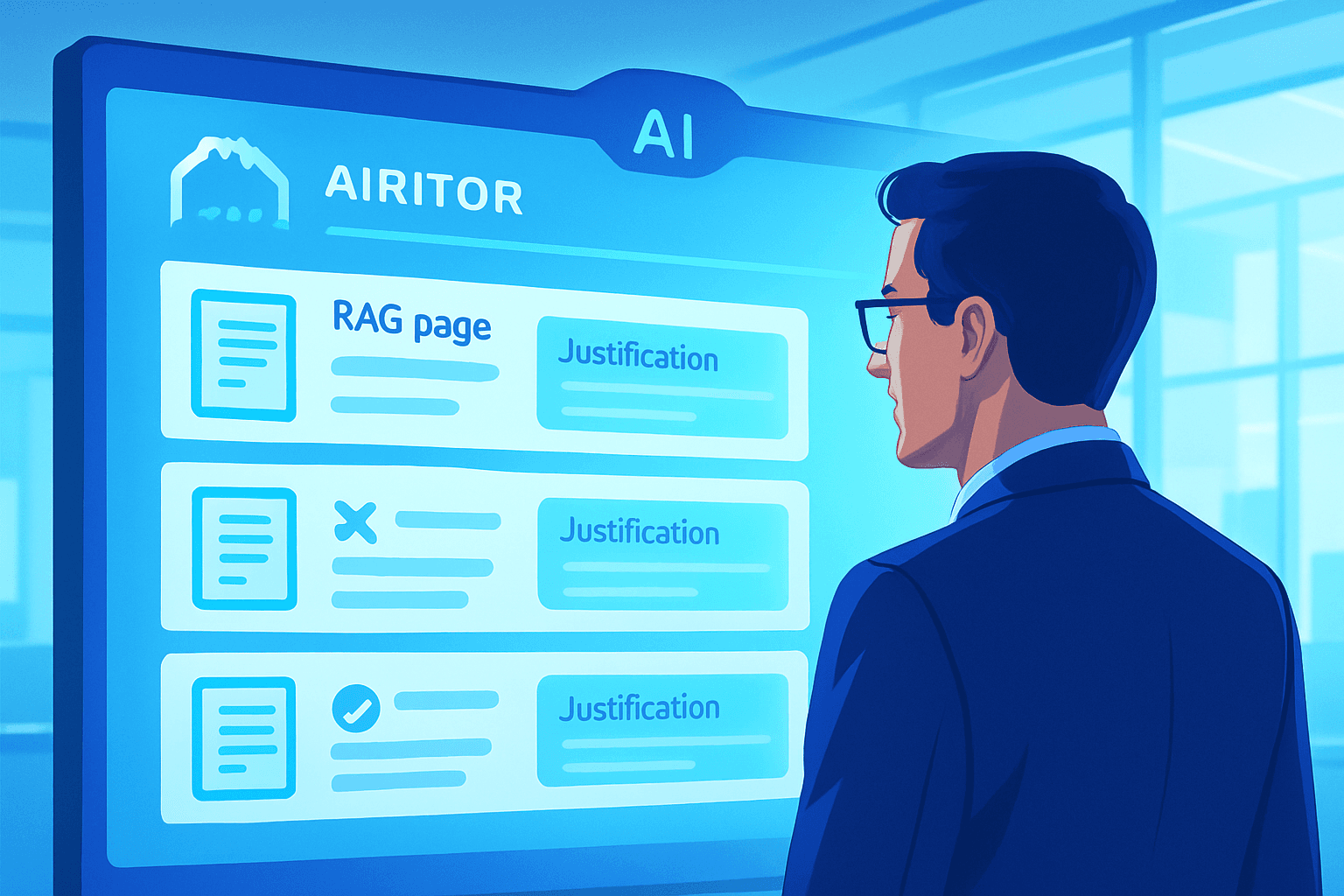
Arbiter : le LLM qui optimise la sélection de pages RAG
Modèles de Langage de Grande Taille
Laisser un LLM choisir la bonne page RAG : le modèle Arbiter à la fin de la récupération.
Cet article fait partie de la série Enterprise Document Intelligence, qui construit un système RAG d'entreprise à partir de quatre briques : parsing, parsing de questions, récupération et génération. Il clôt les trois parties de la brique. La partie précédente, Article 7B (détection d'ancrage), a produit des candidats classés ; celle-ci arbitre : un appel LLM classe les candidats avec des raisons, et la sortie est un objet JSON typé qu'un auditeur peut défendre.
Récupération
La récupération consiste à filtrer sur line_df et toc_df, ancre contre contexte : le modèle mental de l'Article 7A (récupération comme filtrage). Les ancres elles-mêmes proviennent d'un pipeline de détection en trois étapes (Article 7B, détection d'ancrage) : mots-clés + embeddings en parallèle, agrégation en une unité structurelle, puis un seul appel LLM à la fin. Cet article traite de cet appel final.
Cet article concerne cet appel LLM unique. L'arbitre. Il voit les frappes de mots-clés, les frappes d'embeddings et la section dans laquelle chaque candidat se trouve, le tout dans un bref structuré, et rédige un verdict par candidat avec une raison. Le modèle en une ligne : les détecteurs proposent, l'arbitre décide. En un seul appel.
L'article couvre également ce qui entoure l'arbitre : le dispatcher déterministe qui choisit quels détecteurs exécuter par question, le chemin "non trouvé" (un système fiable doit pouvoir dire non), et le contrat JSON unifié (RetrievalResult) que la récupération remet à la génération.
Tout au long de cet article, nous travaillons sur un seul document, Attention Is All You Need (Vaswani et al. 2017, 15 pages ; licence de distribution non exclusive arXiv, déclarée sur la page d'abstract arXiv). Il contient une table des matières native propre dans le plan PDF (22 entrées, 3 niveaux de profondeur), et le contenu est un territoire familier pour tout ingénieur touchant au RAG : encodeur, décodeur, attention, requêtes, clés, valeurs. Cela maintient le focus sur les méthodes de récupération plutôt que sur le parsing d'un corpus spécifique à un domaine. Cet article suppose également que le document porte sa propre table des matières ; la récupération d'une table à partir de texte brut est laissée à un travail ultérieur.
1. L'arbitre LLM : l'appel LLM unique à la fin
C'est l'appel LLM que l'Article 7B (détection d'ancrage) a placé à l'étape 3. Cet article a produit des candidats à partir de chaque détecteur ; cette section traite de ce qui leur arrive. Un candidat est un passage unique qu'un détecteur a renvoyé avec son ancre (où il a été apparié), son unité agrégée (section, page ou morceau), et un extrait de contexte environnant. L'arbitre les voit tous en un seul appel, les classe avec des raisons, et produit la liste finale.
Les trois points couverts dans cette section :
- Pourquoi la fusion de scores (RRF et autres) perd le signal que les détecteurs ont déjà rendu disponible.
- Quel bref structuré remettre à l'arbitre pour qu'il puisse classer avec des raisons.
- Ce qu'il faut enregistrer par candidat afin qu'un auditeur puisse reconstruire la décision.
Le modèle en une ligne : les détecteurs proposent, l'arbitre décide, en un seul appel.
1.1 La fusion de scores est le mauvais instinct
Lorsque plusieurs méthodes renvoient des candidats, le réflexe est de combiner leurs scores. Les méthodes renvoient des chiffres sur différentes échelles : similarité cosinus, BM25 non borné, et comptes d'occurrence entiers. Les additionner n'a pas de sens. Normaliser le score de chaque méthode n'aide pas non plus, car un 0.9 cosinus et un 0.9 BM25 normalisé ne signifient pas la même chose à propos du même candidat.
La réponse classique est la Fusion de Rang Réciproque (RRF). Elle contourne le problème de calibration en ignorant les scores et en utilisant les rangs :
- RRF : fusion basée sur le rang qui ignore les scores bruts ; k = 60.
Les candidats classés par plusieurs méthodes accumulent des contributions ; les candidats vus par une seule méthode obtiennent un petit terme unique. RRF est le défaut dans de nombreuses bases de données vectorielles (Pinecone, Weaviate, Elastic) et fonctionne sur des cas communs sans réglage.
Mais RRF laisse un vrai signal sur le sol. Pourquoi une méthode a classé un candidat est important. La TOC l'a classé parce qu'un titre de section correspondait. Les mots-clés l'ont classé parce que "premium" et "€" co-occurraient sur la même ligne. Les embeddings l'ont classé parce que quelque chose près de la page était vaguement proche dans l'espace vectoriel. RRF compresse tout cela en un index de rang. L'accord entre les méthodes devient un chiffre, et la raison de cet accord disparaît.
C'est exactement ce qu'un expert lit sur l'écran : le titre de section, les mots-clés appariés, les lignes autour de l'appariement. Nous soutenons qu'un petit appel LLM, donné les mêmes informations sous une forme structurée, classe mieux que toute méthode de fusion de scores.
Nous enregistrons toujours RRF lorsque l'outil environnant l'utilise par défaut, ou l'utilisons comme un pré-filtre bon marché lorsque le pool de candidats est trop large pour tenir dans un appel LLM (top-200 par RRF, puis LLM sur les survivants). Mais la décision de classement appartient au LLM, pas à une formule de score.
1.2 Remettre à l'LLM un bref structuré
Le LLM est la couche qui classe. Son entrée n'est pas "voici cinq passages, choisissez le meilleur". C'est un bref structuré, une ligne par candidat, listant ce que chaque méthode de récupération a trouvé :
- candidate_id : référence stable (page + plage de lignes, ou section + décalage de ligne).
- methods : quelles méthodes de récupération ont montré ce candidat (TOC, mots-clés, embeddings).
- section : la section TOC dans laquelle se trouve le candidat, extraite de toc_df.
- matched_keywords : les mots-clés de la question analysée qui ont atterri sur ce candidat.
- snippet : trois à cinq lignes de contexte environnant, extraites de line_df.
Le bref est ce que le LLM lit. Cela ressemble à ce qu'un expert voit sur son écran : un titre de section en haut, les mots-clés appariés dans le corps, les lignes autour de l'appariement. Beaucoup plus proche de cela que d'une liste classée de scores cosinus. Le LLM classe les candidats et écrit une raison en une ligne par candidat retenu, qui va directement dans la piste d'audit. Chaque candidat obtient l'un des quatre rôles :
- primary : porte la réponse.
- supporting : donne le contexte dont la réponse a besoin pour avoir du sens.
- tangential : lié mais maintenu en priorité basse.
- discarded : le rejet du LLM, avec une raison enregistrée pour l'audit.
class CandidateBrief(BaseModel):
candidate_id: str
methods: list[str]
matched_keywords: list[str]
class CandidateRanking(BaseModel):
candidate_id: str
role: Literal["primary", "supporting", "tangential", "discarded"]
briefs: list[CandidateBrief],
) -> list[CandidateRanking]:
"""Lire les briefs structurés, retourner un classement par candidat."""
Un arbitre minimal fonctionnel. Un appel LLM, toute la liste de candidats à la fois, sortie structurée en retour.
def llm_rank(question: str, briefs: list[CandidateBrief], client) -> list[CandidateRanking]:
"""Remettre au LLM les briefs structurés, obtenir un rôle + raison par candidat."""
briefs_text = "\\n".join(
f"[{b.candidate_id}] section={b.section!r}, methods={b.methods}, "
f"matched={b.matched_keywords}, snippet={b.snippet!r}"
f"Question: {question}\\n\\nCandidates:\\n{briefs_text}\\n\\n"
"Pour chaque candidat, attribuer un rôle (primary, supporting, tangential, "
"discarded) et une raison en une ligne. Utiliser le candidate_id tel quel."
)
return client.responses.parse(
model=model_chat,
text_format=ArbiterOutput,
).output_parsed.rankings
Pourquoi cela surpasse la fusion de scores :
-
Le LLM voit pourquoi chaque méthode a classé le candidat. Un match à haute similarité cosinus sans chevauchement de mots-clés est probablement du bruit thématique. Un accord TOC + mots-clés est un vrai signal structurel. RRF transforme les deux en le même numéro de rang.
-
Le LLM peut étiqueter les candidats au-delà de garder/rejeter : primaire, de soutien, tangent. Utile lorsque la réponse a une partie principale et un contexte de soutien.
-
Le LLM peut signaler des contradictions : deux passages disant des choses différentes sur le même point. Commun dans les contrats avec amendements, dans les dépôts réglementaires avec révisions.
-
La justification est en texte clair et va directement dans la piste d'audit. Pas de ligne rrf_score = 0.0327 à expliquer à la conformité.
Coût : un appel LLM (environ une seconde pour un pool de candidats top-10). Moins cher que de faire fonctionner des embeddings sur tout le document. Beaucoup moins cher qu'une mauvaise réponse en production.
1.3 Conflits et la piste d'audit
Lorsque les méthodes ne sont pas d'accord, le LLM doit choisir. Trois règles de base aident :
-
Faire confiance à la TOC sur les correspondances exactes de titres. L'auteur a écrit ce titre. 3.5 Positional Encoding a directement correspondu aux mots-clés de la question en cours. Aucun méthode statistique ne devrait outrepasser cela.
-
Faire confiance aux mots-clés de co-occurrence avec un signal fort. Une ligne où les mots-clés primaires et secondaires apparaissent ensemble (positional + sinusoidal, ou positional + learned) est presque certainement pertinente.
