La recherche en IA te passionne ?
Les papers et avancées qui comptent, expliqués simplement, chaque soir. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
Deloitte prévoit qu'à l'horizon 2027, la moitié des entreprises qui utilisent l'intelligence artificielle générative auront mis en place des projets pilotes ou des preuves de concept autour de l'IA agentique. Cette adoption rapide et généralisée a conduit à une utilisation fréquente du terme "agentique" pour désigner presque tout ce qui implique un appel à un modèle de langage de grande taille (LLM). Cela peut aller d'un processus en cinq étapes avec une intervention de GPT pour un résumé, à un système entièrement autonome qui planifie son propre parcours sans script prédéfini.
Cependant, ces concepts ne sont pas équivalents. Les confondre peut mener à deux erreurs majeures : soit sur-ingénier un processus simple avec une autonomie inutile, soit sous-estimer un problème complexe en l'enfermant dans un cadre rigide qui échoue dès que la réalité diverge du plan initial.
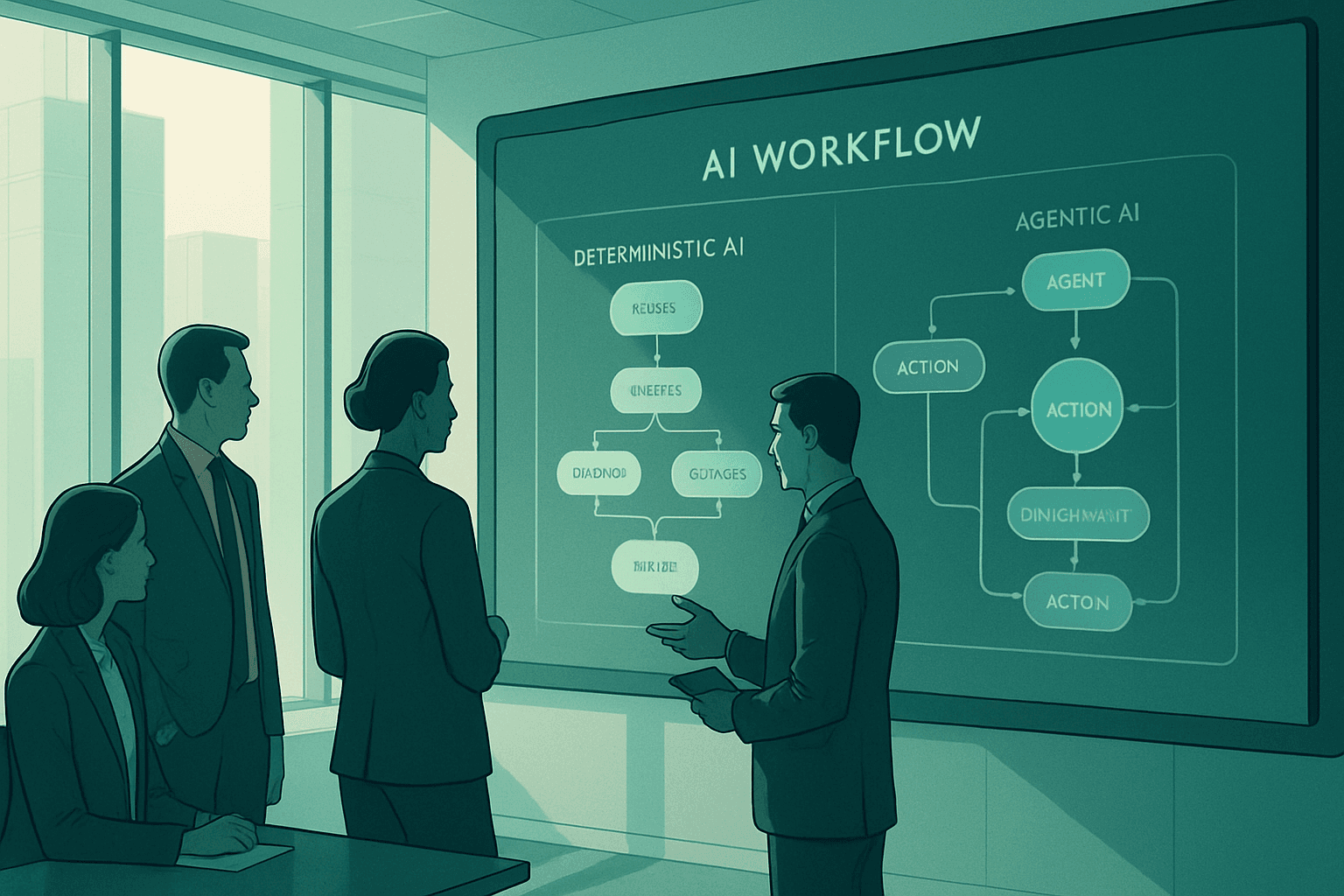
Anthropic, dans son article influent "Building Effective Agents", établit une distinction claire : les flux de travail sont des systèmes où les LLM et les outils sont orchestrés par des chemins de code prédéfinis, tandis que les agents sont des systèmes où les LLM dirigent dynamiquement leur propre processus et l'utilisation des outils, gardant le contrôle sur la manière dont ils accomplissent une tâche. Cet article explore le spectre complet des flux de travail déterministes, des systèmes orchestrés, des agents réactifs uniques et des systèmes multi-agents autonomes, avec du code à chaque étape pour rendre la distinction de contrôle de flux concrète plutôt qu'abstraite.
L'axe réel n'est pas "IA vs. Pas d'IA" : c'est Prévisibilité vs. Autonomie
Avant de comparer les architectures, il est crucial de reformuler la question. La question n'est pas de savoir si un système utilise un LLM, car pratiquement tous le font aujourd'hui. Les vraies questions sont : ce processus doit-il être répétable, auditable et explicable étape par étape ? Et : le chemin correct est-il connu à l'avance, ou le système doit-il le découvrir en temps réel ?
Un système peut s'appuyer fortement sur un LLM tout en restant entièrement déterministe dans sa structure : un pipeline fixe où une étape appelle un modèle pour la génération de texte, mais l'étape suivante est codée en dur, indépendamment de ce qui est renvoyé. Un système peut également être "agentique" avec très peu d'autonomie réelle : une boucle strictement scriptée avec seulement deux actions autorisées et une limite d'étapes. La présence d'un appel à un LLM n'est pas le signal. La propriété du contrôle de flux l'est.
La documentation des modèles de conception de Google Cloud trace cette ligne de manière opérationnelle : les flux de travail déterministes incluent des tâches avec un chemin clairement défini connu à l'avance, où les étapes ne changent pas beaucoup d'une exécution à l'autre. Les flux de travail nécessitant une orchestration dynamique impliquent des problèmes où l'agent doit déterminer la meilleure façon de procéder, sans script prédéfini. C'est le spectre que cet article explore, étape par étape.
Flux de travail déterministes
C'est la base. Un flux de travail déterministe a une séquence connue d'étapes décidées au moment de la conception, par un humain, dans le code. Un LLM peut être intégré à n'importe quelle étape — générant du texte, classifiant des entrées, rédigeant un résumé — mais il ne choisit pas ce qui se passe après l'exécution de sa propre étape. Le code d'orchestration s'en charge, indépendamment de ce que le modèle renvoie.
# deterministic_pipeline.py
# Prérequis : aucun au-delà de la bibliothèque standard de Python
# Exécuter : python deterministic_pipeline.py
def mock_llm_classify(text: str) -> str:
"""
Appel simulé à un LLM -- remplace un appel API réel pour rendre cet exemple
exécutable sans clé API. Le point est structurel : quoi que cela
renvoie, la fonction suivante à exécuter est déjà décidée ci-dessous.
"""
if "remboursement" in text.lower() or "facture" in text.lower():
return "facturation"
return "général"
def extract(raw_input: str) -> str:
"""Étape 1 -- s'exécute toujours, mène toujours à l'étape 2. Pas de branchement ici."""
return raw_input.strip()
def classify(cleaned_text: str) -> str:
"""
Étape 2 -- appelle un LLM pour produire une étiquette, mais l'étiquette n'a aucun effet
sur la fonction qui s'exécute ensuite. C'est la partie déterministe : le modèle
remplit une donnée, il n'influence pas le chemin.
"""
label = mock_llm_classify(cleaned_text)
print(f" [classify] LLM a renvoyé l'étiquette='{label}' (information seulement)")
return cleaned_text
def summarize(cleaned_text: str) -> str:
"""Étape 3 -- s'exécute toujours après l'étape 2, indépendamment de l'étiquette de l'étape 2."""
return f"Résumé : {cleaned_text[:40]}..."
def notify(summary: str) -> str:
"""Étape 4 -- s'exécute toujours en dernier. Le chemin est fixé au moment de la conception."""
return f"Notification envoyée : {summary}"
def run_deterministic_pipeline(raw_input: str) -> str:
"""
Le contrôle de flux ici est entièrement écrit par un humain, à l'avance.
Chaque exécution suit le même chemin : extract -> classify -> summarize -> notify.
L'appel au LLM à l'intérieur de classify() produit une étiquette, mais cette étiquette n'est jamais
utilisée pour décider quelle fonction s'exécute ensuite -- c'est une donnée qui circule dans un pipeline fixe.
"""
step1 = extract(raw_input)
step2 = classify(step1)
step3 = summarize(step2)
step4 = notify(step3)
return step4
if __name__ == "__main__":
# Deux entrées que le LLM classifierait complètement différemment
result_1 = run_deterministic_pipeline("Je veux un remboursement pour ma dernière facture")
result_2 = run_deterministic_pipeline("Quelles sont vos heures d'ouverture ?")
print(f"\nRésultat 1 : {result_1}")
print(f"Résultat 2 : {result_2}")
Orchestrated Workflows
C'est le terrain intermédiaire qui est souvent mal étiqueté comme "agentique", et il vaut la peine de ralentir ici car c'est la ligne que la plupart des gens franchissent réellement lorsqu'ils commencent à utiliser ce terme de manière lâche.
Un flux de travail orchestré a toujours un graphe de chemins possibles défini entièrement à l'avance, mais le chemin emprunté dépend désormais d'une décision en temps réel, souvent prise par un appel à un LLM. C'est toujours un flux de travail. Chaque branche qui pourrait être empruntée a été anticipée.




