La recherche en IA te passionne ?
Les papers et avancées qui comptent, expliqués simplement, chaque soir. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
L'évolution rapide des grands modèles de langage et des embeddings vectoriels a propulsé la génération augmentée par récupération (RAG) au premier plan des solutions pour interroger des documents non structurés. Ce processus, qui semble presque magique, permet de télécharger un document, poser une question, et obtenir une réponse pertinente. Cependant, cette magie apparente cache une complexité sous-jacente : la récupération des informations. Souvent, ce n'est pas le modèle de langage lui-même qui échoue, mais bien l'étape de récupération des données.
La recherche par vecteurs denses est une méthode puissante pour identifier des textes sémantiquement similaires. Elle est capable de comprendre que des termes comme « dépenses urbaines » et « dépenses de ville » sont équivalents. Toutefois, elle peut échouer lorsqu'il s'agit de retrouver des informations précises comme un code d'erreur, un numéro de clause contractuelle ou un chiffre financier spécifique, retournant parfois des résultats incorrects avec une grande assurance. À l'inverse, la recherche par mots-clés, telle que BM25, excelle dans la correspondance exacte mais manque de compréhension sémantique. Pour elle, « automobile » et « voiture » sont des entités distinctes, et une question reformulée peut la laisser perplexe.
La réalité est que ni la recherche par vecteurs denses ni celle par mots-clés ne sont universellement supérieures. Chacune a ses forces dans des types de requêtes spécifiques. Dans des documents complexes comme des contrats juridiques, des rapports financiers ou des manuels techniques, les deux approches sont nécessaires. Le système RAG hybride répond à ce besoin en utilisant les deux méthodes de récupération simultanément et en fusionnant leurs résultats grâce à la fusion de rang réciproque (RRF). Cela permet de combiner la compréhension sémantique de la recherche vectorielle avec la précision de la recherche par mots-clés, le tout avec un coût supplémentaire minimal.
Dans cet article, nous allons explorer la construction d'un système RAG hybride complet. Nous utiliserons FAISS pour la recherche dense, BM25 pour la recherche par mots-clés, et la fusion de rang réciproque pour combiner les résultats en une liste unique et mieux classée. LangGraph servira à orchestrer le tout, tandis qu'une interface utilisateur Streamlit permettra de basculer entre les modes de récupération et d'examiner chaque élément et score derrière chaque réponse.
Cas d'utilisation dans le monde réel
Ce système hybride offre des solutions efficaces pour plusieurs cas d'utilisation concrets :
- Les équipes juridiques peuvent interroger des contrats pour trouver à la fois des numéros de clause spécifiques (correspondance exacte) et comprendre l'intention sous-jacente (sémantique).
- Les analystes financiers peuvent poser des questions sur des définitions comme l'EBITDA et obtenir des chiffres de revenus trimestriels dans les rapports de résultats.
- Les ingénieurs de support peuvent rechercher des codes d'erreur dans des manuels techniques tout en posant des questions sur les causes profondes des problèmes.
- Les équipes de recherche peuvent interroger des dizaines d'articles pour obtenir à la fois des citations exactes et des similarités conceptuelles.
Le code complet de ce système est disponible sur GitHub : agentic-ai-usecases/beginner/hybrid-rag.
Le problème de la récupération en mode unique
Avant de plonger dans le code, il est essentiel de comprendre pourquoi la récupération hybride est cruciale.
La recherche par vecteurs denses transforme le texte en embeddings de haute dimension et identifie les voisins les plus proches par similarité cosinus. Elle excelle dans le traitement des paraphrases : une question comme « Quel est le taux de marge bénéficiaire ? » peut trouver des réponses telles que « revenu net en pourcentage des revenus », même si aucun mot ne chevauche la requête initiale. Cependant, elle peut passer à côté d'éléments importants comme ERR_4021 si ce token est rare dans les données d'entraînement et se situe dans une région peu fréquentée de l'espace d'embedding.
BM25, de son côté, est un algorithme classique de récupération d'information qui se base sur la fréquence des termes et la fréquence inverse des documents. Il évalue les documents en fonction du nombre de mots de la requête présents et de la rareté de ces mots dans l'ensemble du corpus. Il est efficace pour trouver des correspondances exactes, des numéros de pièces, des entités nommées et des terminologies spécifiques. Sa faiblesse réside dans son manque de compréhension sémantique, ce qui fait que des termes comme « automobile » et « voiture » sont perçus comme totalement distincts.
Récupération hybride
La récupération hybride combine ces deux approches. La liste classée fusionnée met en avant des éléments qui sont à la fois sémantiquement et lexicalement pertinents, ce qui est idéal lorsque le document contient un mélange de termes techniques et de prose descriptive.
RRF (Fusion de Reranking Réciproque)
La question cruciale est de savoir comment prioriser les éléments. La réponse réside dans la RRF.
La RRF est un algorithme de fusion basé sur le classement qui combine plusieurs listes classées en un seul classement unifié, sans se soucier des valeurs de score brutes de chaque récupérateur individuel. Plutôt que de demander « quel élément a obtenu le meilleur score global ? », elle se demande « quel élément est apparu près du sommet des listes les plus nombreuses ? ».
Étapes de RRF
La formule est simple :
RRF score(d) = Σ 1 / (k + rank(d, list))
où k est une constante de lissage (typiquement 60) et rank(d, list) est la position indexée à 1 de l'élément d dans la liste de résultats d'un récupérateur donné. La somme s'effectue sur chaque récupérateur ayant retourné l'élément.
Propriétés de RRF
Plusieurs propriétés rendent la RRF particulièrement adaptée à la récupération hybride :
-
Indépendance de l'échelle des scores : La similarité cosinus de FAISS se situe dans la plage [-1, 1], tandis que les scores de BM25 sont illimités et dépendent de la longueur des documents. Ces deux nombres ne sont pas comparables, et la RRF contourne ce problème en convertissant d'abord tout en rangs.
-
Récompense l'accord inter-listes : Un élément qui se classe 1er dans BM25 et 2ème dans la recherche vectorielle obtient un score plus élevé qu'un élément qui se classe 1er dans une seule liste. L'étape de fusion amplifie l'accord, ce qui est exactement le signal recherché.
-
Robustesse aux valeurs aberrantes : Un seul récupérateur qui retourne avec confiance un mauvais élément au rang 1 ne peut contribuer qu'à 1 / (60 + 1) ≈ 0,016 au score RRF. Si l'autre récupérateur n'a pas retourné cet élément du tout, il ne se rapproche pas du sommet. En pratique, cela signifie que lorsque les deux récupérateurs s'accordent sur un élément, il monte au sommet. Lorsque seul un récupérateur le fait ressortir, il obtient tout de même du crédit mais pas assez pour dominer si un autre élément avait un soutien plus large.
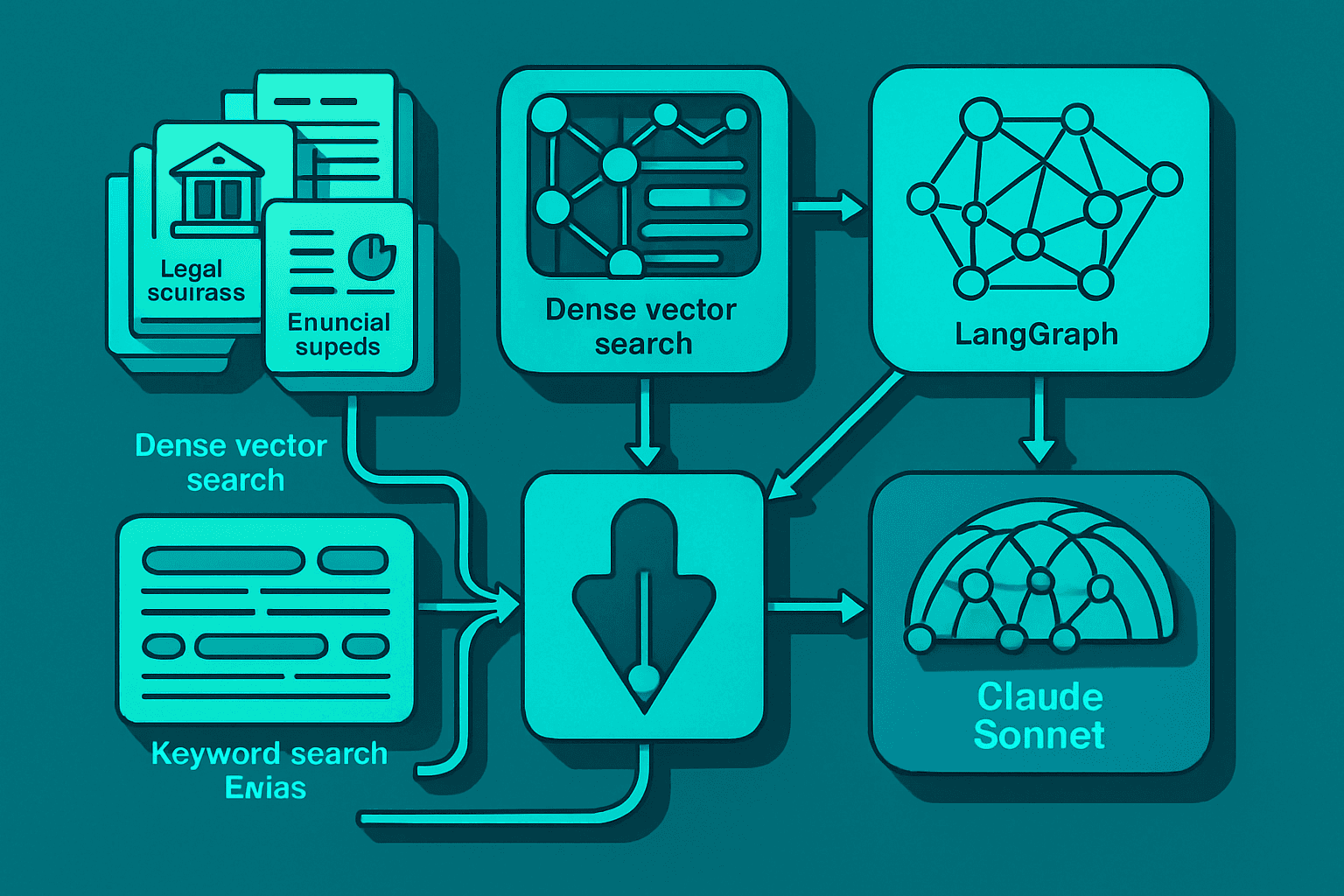
Architecture du système
Voici l'architecture complète de ce que nous allons construire :
Remarque sur l'architecture : Une décision de conception clé est l'utilisation conjointe de FAISS et BM25 pour maximiser la précision et la pertinence des résultats de recherche.

