La recherche en IA te passionne ?
Les papers et avancées qui comptent, expliqués simplement, chaque soir. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
L'évolution rapide des technologies de traitement du langage naturel a mis en lumière l'importance des systèmes de génération augmentée par la récupération (RAG). Ces systèmes sont devenus essentiels pour interroger efficacement des documents non structurés. En théorie, il suffit de télécharger un document, de poser une question, et le système fournit une réponse. Cependant, la réalité est plus complexe. Le véritable défi réside souvent dans la phase de récupération des informations pertinentes, plutôt que dans le modèle de langage lui-même. En effet, le mode de défaillance silencieuse de la plupart des systèmes RAG se situe précisément à cette étape de récupération.
La recherche vectorielle dense, par exemple, est très efficace pour identifier des textes sémantiquement similaires. Elle peut comprendre que les termes "dépenses urbaines" et "dépenses de la ville" désignent la même chose. Toutefois, elle peut échouer lorsqu'il s'agit de retrouver des informations précises telles qu'un code d'erreur, un numéro de clause de contrat ou un chiffre financier. Dans ces cas, elle peut silencieusement retourner les mauvais éléments avec une grande confiance. À l'inverse, la recherche par mots-clés, comme celle effectuée par l'algorithme BM25, excelle dans la recherche de correspondances exactes, des numéros de pièces, des entités nommées et une terminologie spécifique. Cependant, elle manque de compréhension sémantique, ce qui peut poser problème pour des requêtes paraphrasées.
Aucun de ces systèmes n'est universellement supérieur. Chacun a ses forces et ses faiblesses, ce qui rend la combinaison des deux dans un système RAG hybride particulièrement intéressante. Ce système utilise la fusion de classement réciproque pour intégrer les résultats des deux méthodes, offrant ainsi une liste de résultats classés qui bénéficie à la fois de la précision de la recherche par mots-clés et de la compréhension sémantique de la recherche vectorielle, sans coût supplémentaire significatif.
Cas d'utilisation dans le monde réel
Le système RAG hybride trouve des applications dans divers domaines professionnels. Par exemple, les équipes juridiques peuvent l'utiliser pour rechercher des clauses spécifiques dans des contrats tout en comprenant l'intention sous-jacente. Les analystes financiers peuvent poser des questions sur des termes comme l'EBITDA ou sur des chiffres précis dans des rapports financiers. Les ingénieurs de support peuvent rechercher des codes d'erreur dans des manuels techniques tout en obtenant des explications sur les causes sous-jacentes. Enfin, les équipes de recherche peuvent analyser de nombreux articles pour trouver à la fois des citations exactes et des similarités conceptuelles.
Pour ceux qui souhaitent explorer le code complet de ce système, il est disponible sur GitHub : agentic-ai-usecases/beginner/hybrid-rag.
Le problème de la récupération à mode unique
Avant de se plonger dans les détails techniques, il est crucial de comprendre pourquoi une approche hybride est nécessaire. La recherche vectorielle dense transforme le texte en embeddings de haute dimension et utilise la similarité cosinus pour trouver les éléments les plus proches. Elle est idéale pour le paraphrasage, mais peut ignorer des éléments spécifiques comme un code d'erreur peu fréquent.
L'algorithme BM25, quant à lui, est basé sur la fréquence des termes et leur rareté dans le corpus. Il est excellent pour trouver des correspondances exactes, mais il ne comprend pas les nuances sémantiques. Ainsi, des termes comme "automobile" et "voiture" sont traités comme complètement différents.
Récupération hybride
La récupération hybride combine les forces des deux approches. Elle produit une liste classée qui met en avant des éléments à la fois sémantiquement et lexicalement pertinents. Cela est particulièrement utile dans des documents contenant un mélange de termes techniques et de texte descriptif.
La question cruciale est de savoir comment prioriser les éléments. La fusion de classement réciproque (RRF) offre une solution efficace.
Fusion de classement réciproque (RRF)
La fusion de classement réciproque est une méthode qui combine plusieurs listes classées en un seul classement unifié. Plutôt que de se concentrer sur les scores bruts, elle s'intéresse à la position des éléments dans chaque liste.
La formule de RRF est la suivante :
RRF score(d) = Σ 1 / (k + rank(d, list))
Ici, k est une constante de lissage, généralement fixée à 60, et rank(d, list) représente la position de l'élément dans la liste de résultats d'un récupérateur. La somme est calculée pour chaque récupérateur ayant retourné l'élément.
Propriétés de RRF
Plusieurs propriétés rendent RRF particulièrement adapté à la récupération hybride :
-
Indépendance de l'échelle des scores : Les scores de similarité cosinus de FAISS varient entre -1 et 1, tandis que ceux de BM25 sont non bornés et dépendent de la longueur des documents. RRF contourne ce problème en convertissant les scores en rangs.
-
Récompense l'accord inter-listes : Un élément bien classé dans les deux listes obtient un score plus élevé, ce qui amplifie l'accord entre les récupérateurs.
-
Robuste aux valeurs aberrantes : Un récupérateur qui classe incorrectement un élément en tête ne peut pas dominer le classement final si l'autre récupérateur ne le soutient pas.
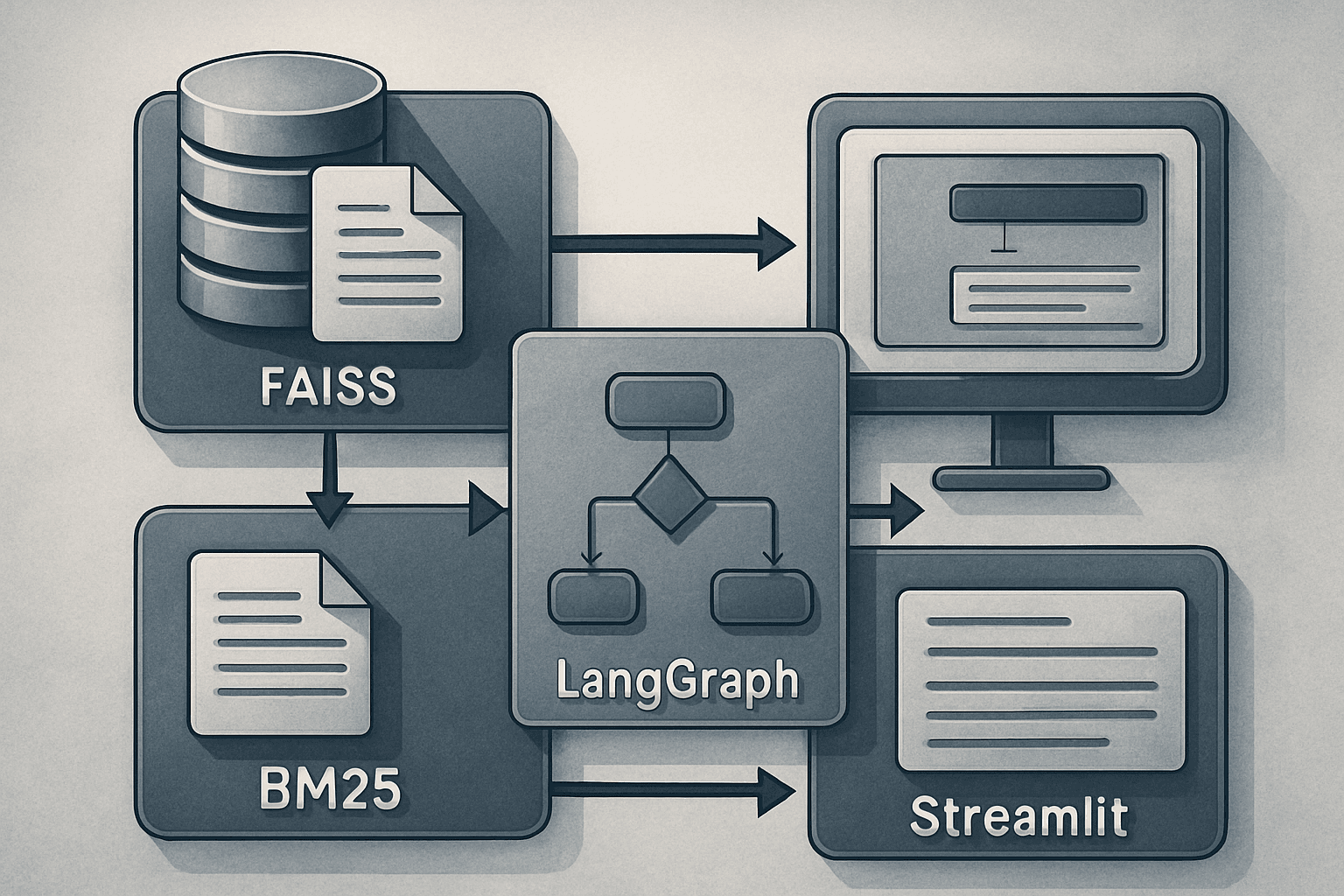
Architecture du système
L'architecture complète de ce système RAG hybride repose sur l'intégration de FAISS pour la recherche dense et BM25 pour la recherche par mots-clés. La fusion de classement réciproque permet de combiner efficacement les résultats. LangGraph orchestre le processus, tandis qu'une interface utilisateur Streamlit permet de basculer entre les modes de récupération et d'inspecter chaque élément et score derrière chaque réponse.