La recherche en IA te passionne ?
Les papers et avancées qui comptent, expliqués simplement, chaque soir. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
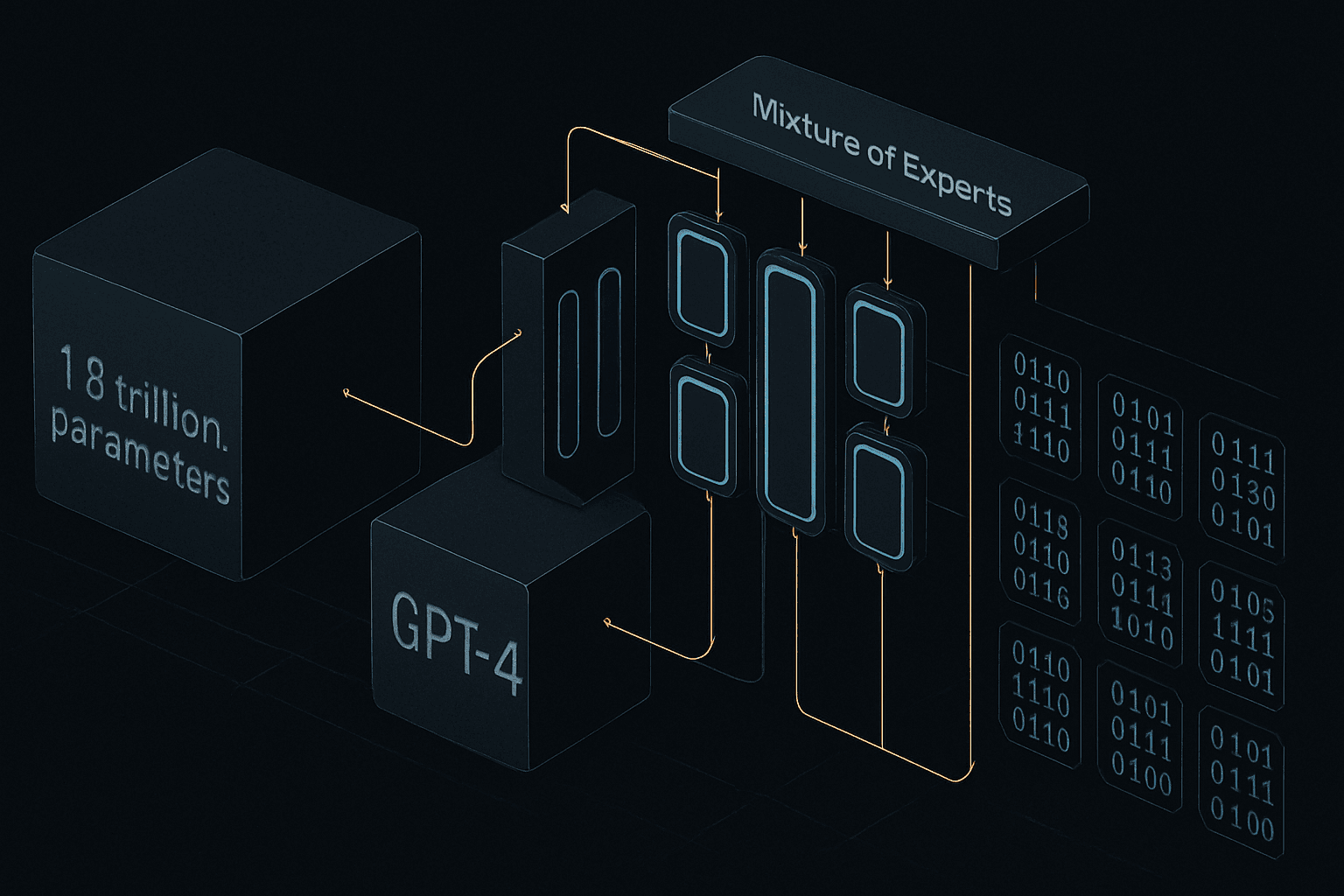
Une architecture impressionnante pour GPT-4
Le modèle GPT-4 se distingue par ses 1,8 trillion de paramètres, bien qu'il n'en utilise qu'une fraction, soit 2 % par token. Cette caractéristique met en avant une efficacité ciblée dans le traitement des données.
L'article explore les modèles d'apprentissage automatique, en mettant l'accent sur le nombre de paramètres et leur efficacité opérationnelle. L'architecture Mixture of Experts (MoE) est examinée pour comprendre comment différents modèles utilisent ces paramètres par token et comment le routage influence les performances. Cette approche permet d'améliorer la stabilité et l'efficacité de l'entraînement en utilisant plusieurs experts pour le traitement des tokens.
Comparaison avec DeepSeek-R1
Un autre modèle, DeepSeek-R1, est également abordé. Il dispose de 671 milliards de paramètres, avec 37 milliards actifs par token. L'article explore les mises en œuvre spécifiques de ce modèle et le compare avec des architectures existantes pour éclairer les avantages en termes de calcul et d'utilisation de la mémoire. Cette comparaison met en lumière les innovations dans le domaine de l'apprentissage automatique et les implications pour le développement futur des modèles d'intelligence artificielle.
Ces avancées technologiques soulignent l'importance de l'optimisation des ressources en calcul et en mémoire, ouvrant la voie à des modèles d'IA plus performants et économes en ressources.
