CEO-Bench: Only Three AIs Overcome the 500-Day Challenge
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
CEO-Bench: Only Three AIs Overcome the 500-Day Challenge
Three AI models finished above the starting capital in a 500-day startup survival test.
Researchers from Princeton University designed CEO-Bench, a test where AI agents must manage a fictional software company for 500 simulated days. Most current models go bankrupt, and a simple rule-based heuristic without AI outperforms nearly all others.
AI agents excel at specific tasks: fixing a bug, following a service policy during a conversation, or completing an online workflow. These tasks share a simple structure, according to the Princeton study: the agent receives a clear goal, acts briefly, and receives quick feedback. However, many important tasks in the real world do not resemble this. They involve long chains of decisions under uncertainty, where prioritization, allocation of limited resources, interpretation of noisy signals, and adaptation to changing conditions are required.
To precisely test these skills, the researchers developed CEO-Bench. The benchmark simulates a realistic example of this type of long-term task: managing a startup over 500 simulated days.
The researchers cite a famous example: in 1997, Apple was 90 days away from bankruptcy. Steve Jobs sketched a simple two-by-two grid—consumer and professional, desktop and portable—and decided that Apple would only build products for these four quadrants. The iMac, iPod, and iPhone followed.
This type of strategic intelligence is fundamentally different from what AI agents do today, the authors argue. Agents quickly improve at individual tasks. But leading an entire organization toward long-term goals? That's a completely different problem. CEO-Bench is a first attempt to measure exactly this "steering intelligence."
An AI CEO for a Fictional Software Company
In CEO-Bench, an agent manages a fictional subscription software company called NovaMind. It starts with zero customers and one million dollars in the bank. Performance is measured by the remaining cash at the end. If the balance falls below zero even once, the company goes bankrupt, and the simulation ends.
The agent controls the company via a Python API with 34 tools and a database of 19 tables. Instead of simply issuing individual commands, it writes its own code, queries the database with SQL, and builds custom workflows from the results. This confronts it with the same challenges as a human CEO, according to the researchers.
In the 500-day startup simulation, the agent connects database queries, interactions with management tools, and social media posts with market cycles and outcome indicators such as ticket resolutions, subscriber growth, cancellations, and available cash.
Delayed Feedback and Hidden Variables Make the Test Challenging
What makes the task difficult is time and uncertainty. Decisions unfold over realistic business timelines: revenues only arrive on billing dates, R&D projects take days to weeks, and errors often manifest later through cancellations or reputational damage. Costs are immediate. The agent must spend money whose return on investment may not be seen for weeks.
Much of the company's state remains hidden. The agent cannot directly see customer satisfaction, willingness to pay, or minimum quality expectations. It must reconstruct these elements from noisy signals such as cancellations, support tickets, or social media reactions. The simulation models 26 customer segments and individual customers, each with its own budgets, price sensitivities, and expectations.
The world also continues to change. Competitors periodically raise customer quality expectations, preferences evolve over time, and a simulated economic cycle affects demand and willingness to pay, forcing the agent to adjust constantly.
The researchers deliberately chose fixed and transparent rules rather than a language model as an arbiter. They wanted to avoid a weakness they see in Vending-Bench, a test with a simulated vending machine: there, a simulated AI supplier can reward an agent for unrealistic verbal promises.
Most Models Go Bankrupt
Among fourteen models tested, most fail at the task. Almost all can generate valid orders and database queries, but none can maintain a consistent strategy over time. Many go bankrupt before the end of the simulation.
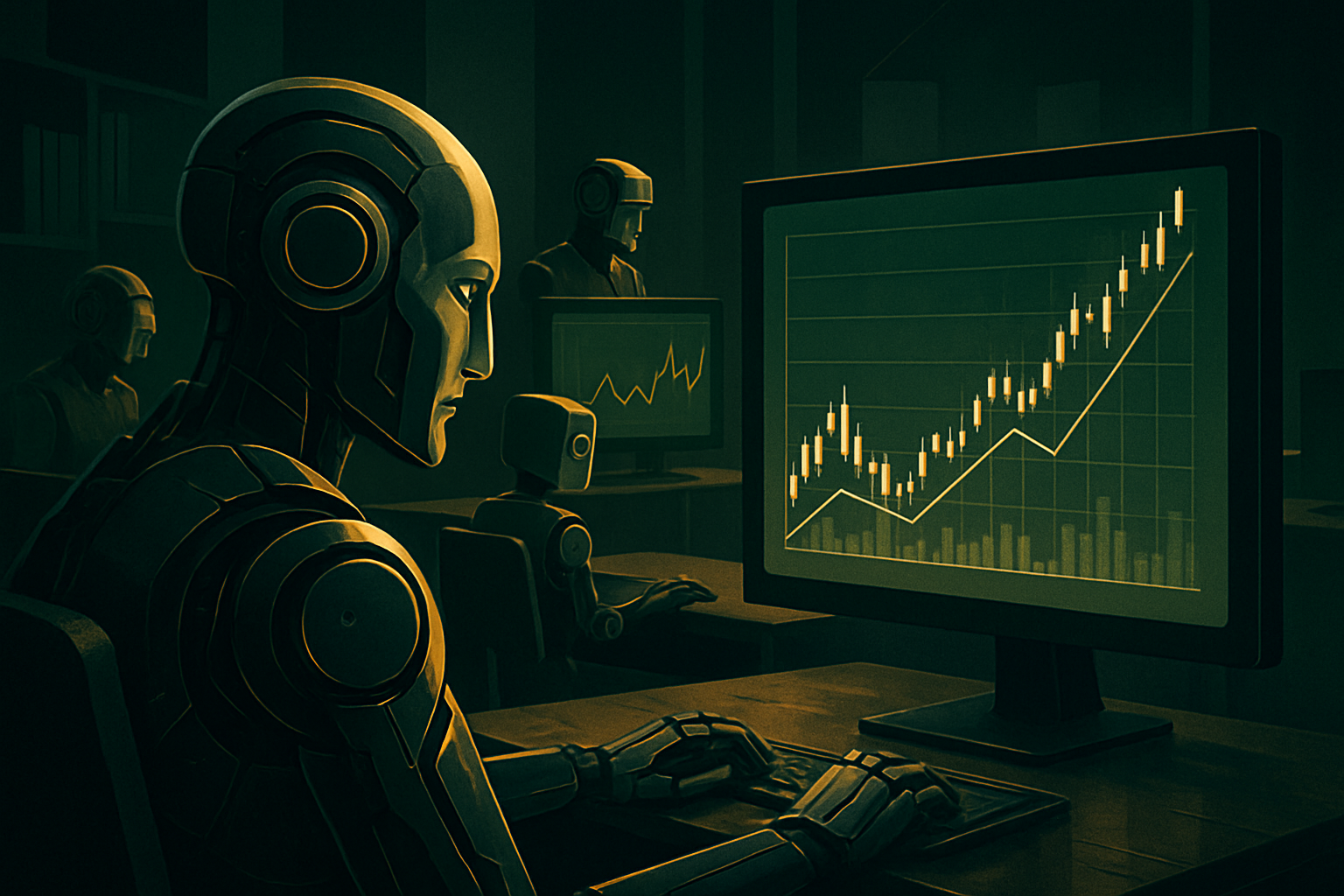
Only three models finish their best run above the starting capital of one million dollars: Claude Fable 5 at $47.15 million, Claude Opus 4.8 at $27.8 million, and GPT-5.5 at $21.3 million. Claude Fable 5 is the only model to exceed the starting capital in multiple runs.
However, there is a caveat. One run of Fable 5 was interrupted because the model refused to continue, and in the other two, some requests reverted to Opus 4.8. GPT-5.5 went bankrupt in two of its three runs.
In the 500-day simulation, the Claude models reach up to $47.15 million in cash, followed by GPT-5.5. Several agents go bankrupt before the end of the run.
The most revealing comparison is with a simple rule-based heuristic that never calls a language model. It sets prices, quotas, and levels, focuses advertising and targeted development on a small set of customer segments, and adjusts capacity based on recent usage. This heuristic achieves $15.76 million, beating all models except Fable 5, Opus 4.8, and GPT-5.5.
The researchers also roughly estimate the upper limit of achievable final cash to be around $2.2 billion. Even the best agents remain far from this goal. The test is not yet maximized, the authors assert.
Exploration Outweighs Caution
Analysis of decision trajectories reveals clear behavioral differences. GPT-5.5 and Claude Opus 4.8 continue to try new strategies as conditions change, whether that means ramping up customer acquisition, adjusting levels, or modifying support and R&D budgets. Claude Opus 4.7, on the other hand, primarily responds to setbacks by cutting costs and preserving cash. This passive approach allows the model to survive until the end but prevents it from making a profit.
Interestingly, Opus 4.8 and GPT-5.5 achieve similar final outcomes through very different paths: Opus 4.8 acquires more customers early but drops to zero customers in the middle of the simulation, while GPT-5.5 maintains its customer base throughout. Both write surprisingly sophisticated code. Opus 4.8 builds its own internal simulation that models customer cohorts to predict future cash flows. GPT-5.5 explores the negotiation history in the database to uncover hidden customer preferences.
The researchers measure four capabilities that correlate with success:
- Discovery of hidden information, such as which advertising channel works best for a given customer segment,
- Prediction of the future, measured by the error in cash flow forecasts over four weeks,
- Rapid adaptation to change, measured by how quickly a model notices a competitive move,
- Forward planning, partially measured by the frequency with which if-then scenarios appear in the agent's notes.
On these four points, Opus 4.8 and GPT-5.5 score above the average of other models.
The Tool Environment Matters Too
Another finding concerns the software environment that agents use to act. The researchers also tested Claude Opus 4.7 with Claude Code and GPT-5.5 with Codex, two popular coding assistants. In both cases, the agents acted much less frequently and achieved poorer results. The researchers suspect that the system prompts in these tools, which are adjusted for software development, are to blame.
Shortening the time horizon does not solve the problem either. When the simulation is compressed to 50 days, only GPT-5.5 manages to finish with a profit. Most models, the researchers conclude, remain weak at coordinating decisions even toward a short-term goal.
The authors acknowledge limitations in their setup. The product is represented by a single quality score as they found no reliable way to assess qualitative changes in the product. Compliance, security, and funding are set aside to make each run economically feasible. Nevertheless, CEO-Bench exposes a gap between the local competence of today's model tools and the ability to link actions over long periods into a coherent strategy, they assert.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.