FAISS and BM25: Claude Sonnet Revolutionizes RAG Search
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
The rapid evolution of natural language processing technologies has highlighted the importance of retrieval-augmented generation (RAG) systems. These systems have become essential for effectively querying unstructured documents. In theory, one simply uploads a document, asks a question, and the system provides an answer. However, the reality is more complex. The real challenge often lies in the phase of retrieving relevant information, rather than in the language model itself. Indeed, the silent failure mode of most RAG systems occurs precisely at this retrieval stage.
Dense vector search, for example, is very effective at identifying semantically similar texts. It can understand that the terms "urban spending" and "city expenses" refer to the same thing. However, it may fail when it comes to retrieving precise information such as an error code, a contract clause number, or a financial figure. In these cases, it may silently return incorrect items with high confidence. Conversely, keyword search, such as that performed by the BM25 algorithm, excels at finding exact matches, part numbers, named entities, and specific terminology. However, it lacks semantic understanding, which can be problematic for paraphrased queries.
Neither of these systems is universally superior. Each has its strengths and weaknesses, making the combination of both in a hybrid RAG system particularly interesting. This system uses reciprocal ranking fusion to integrate the results of both methods, thus providing a ranked list of results that benefits from both the precision of keyword search and the semantic understanding of vector search, without significant additional cost.
Real-World Use Cases
The hybrid RAG system finds applications in various professional fields. For example, legal teams can use it to search for specific clauses in contracts while understanding the underlying intent. Financial analysts can ask questions about terms like EBITDA or specific figures in financial reports. Support engineers can search for error codes in technical manuals while obtaining explanations for underlying causes. Finally, research teams can analyze numerous articles to find both exact citations and conceptual similarities.
For those interested in exploring the complete code of this system, it is available on GitHub: agentic-ai-usecases/beginner/hybrid-rag.
The Single-Mode Retrieval Problem
Before diving into the technical details, it is crucial to understand why a hybrid approach is necessary. Dense vector search transforms text into high-dimensional embeddings and uses cosine similarity to find the closest items. It is ideal for paraphrasing but may overlook specific items like a rare error code.
The BM25 algorithm, on the other hand, is based on term frequency and rarity within the corpus. It is excellent for finding exact matches, but it does not grasp semantic nuances. Thus, terms like "automobile" and "car" are treated as completely different.
Hybrid Retrieval
Hybrid retrieval combines the strengths of both approaches. It produces a ranked list that highlights items that are both semantically and lexically relevant. This is particularly useful in documents containing a mix of technical terms and descriptive text.
The crucial question is how to prioritize the items. Reciprocal ranking fusion (RRF) offers an effective solution.
Reciprocal Ranking Fusion (RRF)
Reciprocal ranking fusion is a method that combines multiple ranked lists into a single unified ranking. Rather than focusing on raw scores, it considers the position of items in each list.
The RRF formula is as follows:
RRF score(d) = Σ 1 / (k + rank(d, list))
Here, k is a smoothing constant, typically set to 60, and rank(d, list) represents the position of the item in the results list of a retriever. The sum is calculated for each retriever that returned the item.
Properties of RRF
Several properties make RRF particularly suited for hybrid retrieval:
-
Score Scale Independence: The cosine similarity scores from FAISS range from -1 to 1, while those from BM25 are unbounded and depend on document length. RRF circumvents this issue by converting scores into ranks.
-
Rewards Inter-List Agreement: An item that is well-ranked in both lists receives a higher score, amplifying agreement between retrievers.
-
Robust to Outliers: A retriever that incorrectly ranks an item at the top cannot dominate the final ranking if the other retriever does not support it.
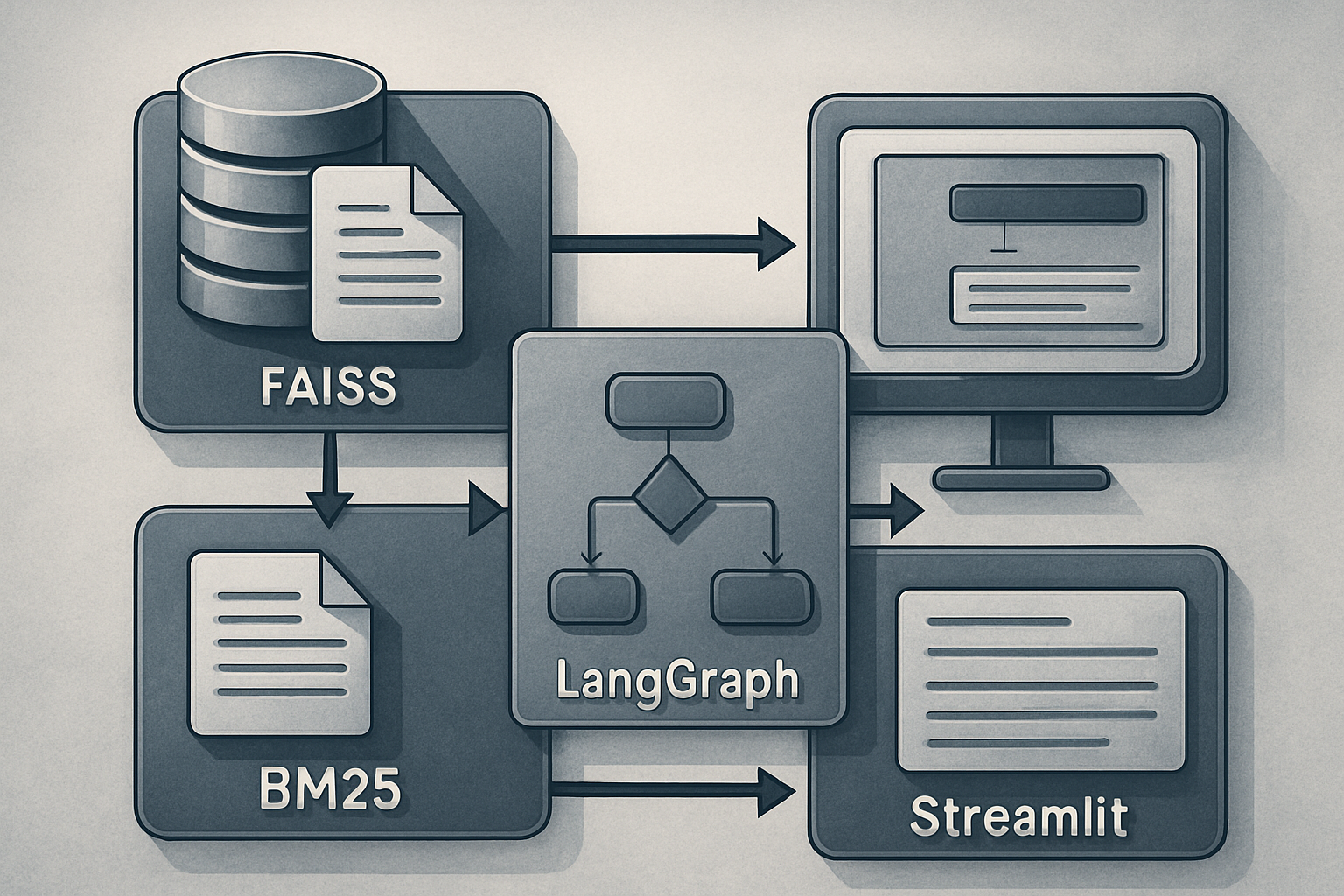
System Architecture
The complete architecture of this hybrid RAG system relies on the integration of FAISS for dense search and BM25 for keyword search. Reciprocal ranking fusion allows for the effective combination of results. LangGraph orchestrates the process, while a Streamlit user interface enables switching between retrieval modes and inspecting each item and score behind each response.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.