Loop Engineering: Revolutionizing AI Agent Reliability
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
The Problem with Current Agent Architectures
In the field of artificial intelligence agents, two dominant models stand out, each with its own limitations. The first, often referred to as "Master Stroke," relies on a single prompt that generates an immediate response. This model is appreciated for its speed and low cost, but it shows its limitations as soon as the task requires multiple steps. In these cases, the model loses sight of the initial context, producing results that seem correct but are not.
The second model, known as "ReAct Loop," follows a cycle of reasoning, action, observation, and repetition. Although this model is the foundation of many modern frameworks such as LangGraph, AutoGen, and the Microsoft Agent Framework, it suffers from a lack of governance. There is no built-in mechanism to determine when to stop, adjust course, or seek human intervention.
Both approaches share a common gap: they consider reliability as an inherent characteristic of the model rather than the system as a whole.
What Loop Engineering Proposes
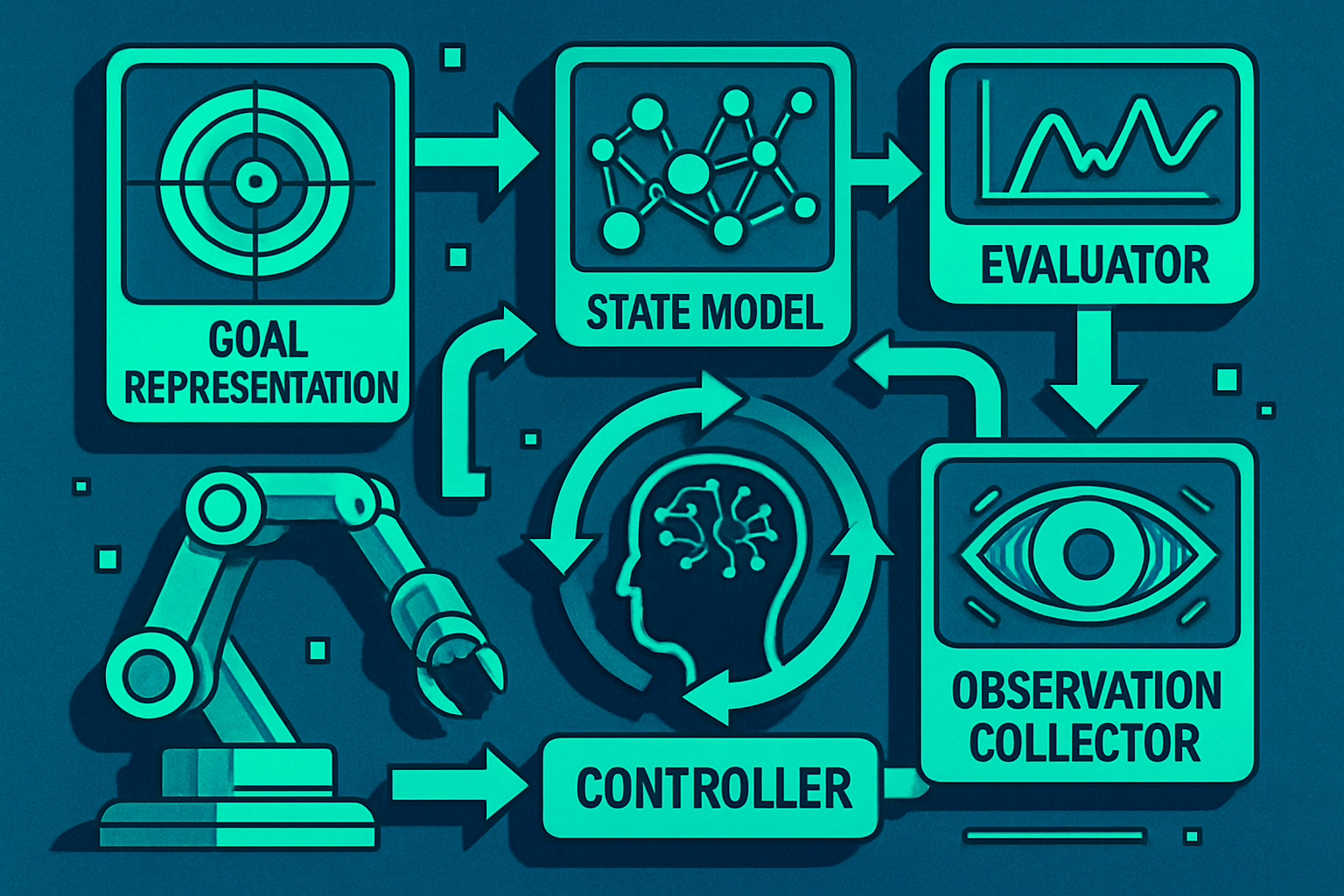
Loop engineering offers a new perspective by reframing the problem. Instead of trying to make the model smarter, it aims to build a governance architecture around the model. Drawing inspiration from control theory, state machines, and reinforcement learning, this approach identifies six essential components to ensure the reliability of agents.
Goal Representation
It is not simply about asking the agent to write a blog post. The task must be defined in a structured manner, including budget, time, and security constraints, as well as success criteria and stopping conditions. Without these elements, the agent navigates without a clear destination.
State Model
This component is divided into five distinct layers:
- Static State: Includes the goal, constraints, and initial configuration.
- Dynamic State: Represents current outputs and intermediate results.
- Tool State: Indicates which tools are available and their status.
- Reflective State: Collects lessons learned from previous iterations.
- Governance State: Includes risk budget, cost, and remaining iterations.
Unlike traditional systems that group these elements into a single context window, loop engineering separates them to allow the agent to clearly distinguish between its goals, past actions, and learnings.
Action Executor
This component establishes a controlled boundary around the use of tools. Each action is subject to a risk assessment before execution, preventing the agent from making potentially costly or destructive decisions without prior authorization.
Observation Collector
The observation collector records what actually happened, regardless of the agent's initial intentions. This distinction is crucial because language models often struggle to self-evaluate accurately. For example, an agent may believe it has saved a file when a permission error has prevented it.
Evaluator
The evaluator analyzes each iteration across four dimensions:
- Confidence: Is the agent sure of its next step?
- Progress: Is it getting closer to the goal or stagnating?
- Drift: Has it strayed from the initial task?
- Risk: Could the next action cause harm or exceed the budget?
Controller
The controller acts as the ultimate decision-maker. Based on the evaluation, it can choose to continue, revise the plan, downgrade an action, escalate to a human, or completely halt execution. This component is often absent in current agent systems, which lack a mechanism to decide whether to continue actions.
Five Types of Loops
Not all tasks require the same loop structure. The document identifies five types of loops, each suited to specific needs. A task can thus go through planning, execution, and verification loops, all wrapped in a governance loop to keep risk under control.
Where Current Architectures Fail
The comparative analysis in the document highlights several weaknesses of current architectures:
- Single-shot agents, while fast and low-cost, lack recovery mechanisms. An initial error requires starting over.
- ReAct loops, although adaptable, lack formal termination conditions and can continue indefinitely without human intervention.
- Workflow-orchestrated agents, such as Prefect, Airflow, and AWS Step Functions, offer good traceability but become fragile when the task deviates from the predefined graph.
- Agents designed according to the loop model are better equipped for situations where the plan must emerge during execution, thanks to dynamic governance applied at each iteration.
The Argument Against What Matters
The document acknowledges a major objection: "Mature workflow orchestration tools already provide state tracking, recovery, and human approval features. Is loop engineering not redundant?" The answer is clear: "Governance controls must be applied at each iteration, as there is no pre-established map of potential failures." Unlike workflow-orchestrated systems where risky steps are predefined, the loop model generates the plan during execution, making each step potentially critical. Thus, pervasive governance is necessary to ensure reliability.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.