t0-alpha: Revolutionizing Time Series with LLMs
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
t0-alpha : révolution des séries temporelles avec les LLMs
Modèles de Langage de Grande Taille
Explication des LLMs pour les séries temporelles avec t0-alpha
Un modèle de langage de grande taille (LLM) pour les séries temporelles, comme t0-alpha, est un prévisionniste probabiliste de 102 millions de paramètres développé par The Forecasting Company, lancé en juin 2026. The Forecasting Company a publié les poids sous la licence Apache-2.0, ce qui permet cette reproduction : le modèle est suffisamment petit pour être exécuté sur du matériel accessible et il est accompagné de résultats GIFT-Eval vérifiables en dehors du laboratoire d'origine.
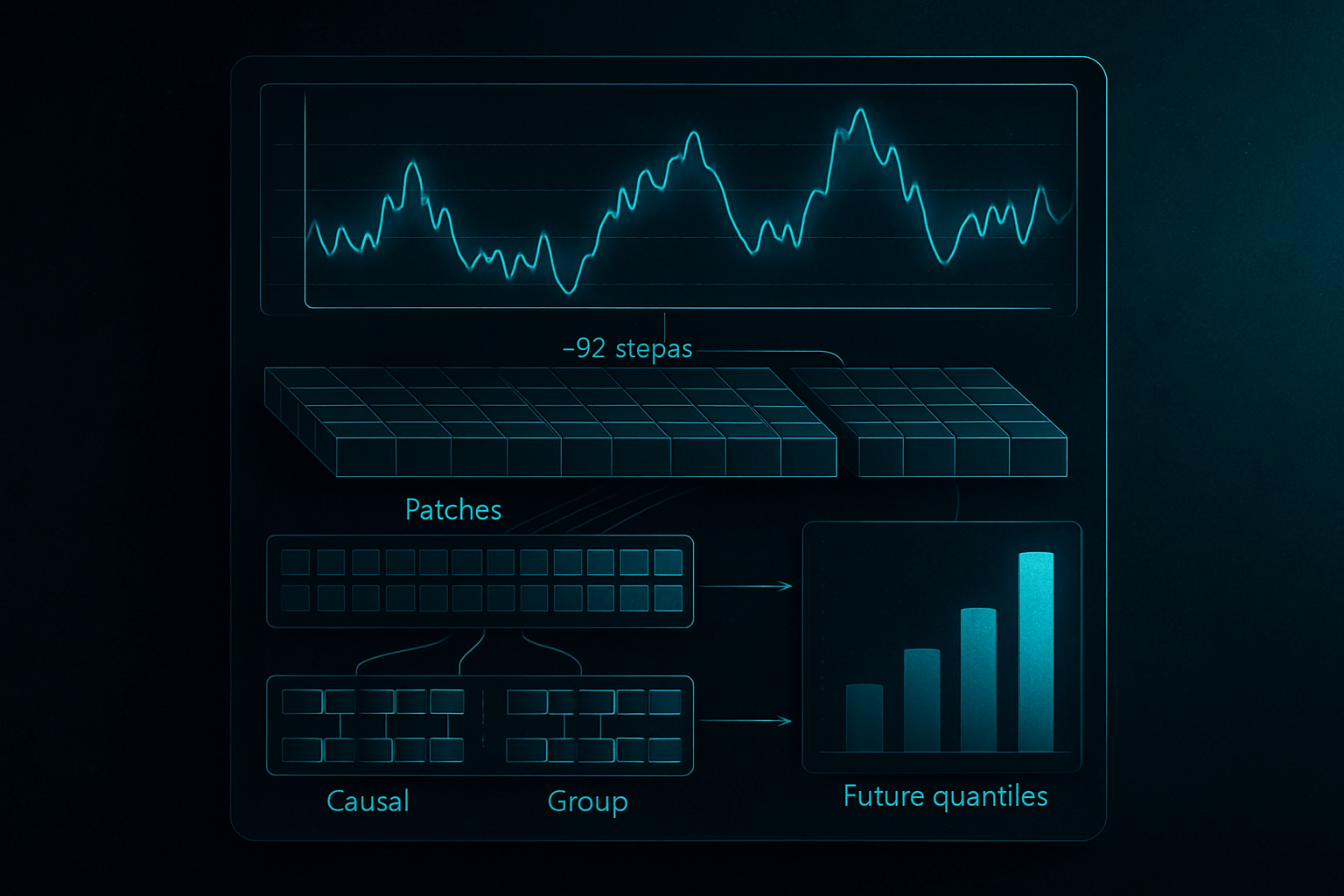
Le modèle illustre la recette de base derrière de nombreux LLMs pour les séries temporelles actuels. Il découpe une séquence numérique en patches, traite ces patches avec un transformer causal, et émet des quantiles au lieu d'une seule ligne future. Cela est suffisamment proche de la modélisation du langage pour rendre l'analogie utile, mais assez différent pour que les détails soient importants.
J'ai également relancé le benchmark. Sur GIFT-Eval, t0-alpha a reproduit exactement ses chiffres principaux rapportés : CRPS 0.4941 et MASE 0.7240.
Configuration du benchmark GIFT-Eval
J'utilise GIFT-Eval comme benchmark principal dans cet article. Il comprend 97 configurations de tâches provenant de 55 ensembles de données à travers sept domaines. Il inclut des horizons courts et longs, des fréquences allant de secondes à annuelles, des séries univariées et multivariées, ainsi que des scores probabilistes.
Les deux métriques principales sont MASE et CRPS.
- Les deux scores sont normalisés par rapport à Seasonal Naive, la référence qui répète la saison précédente. Un score de 1.000 signifie que le modèle correspond à cette référence. Les scores inférieurs à 1.000 sont meilleurs, et ceux supérieurs à 1.000 sont moins bons.
Dans mon exécution, t0-alpha a obtenu un score de 0.4941 CRPS. Sous la normalisation par moyenne géométrique de GIFT-Eval, cela place son erreur probabiliste à environ la moitié de la référence Seasonal Naive.
Comment le modèle transforme une série temporelle
Un modèle de séries temporelles doit créer des tokens à partir de nombres. t0-alpha le fait en découpant l'entrée en fenêtres fixes de 32 étapes temporelles. Chaque fenêtre devient un patch. Le modèle intègre ces patches, les passe à travers un transformer de type décodeur, et prédit des quantiles futurs.
La partie causale est importante. Lorsque t0-alpha prédit la prochaine fenêtre, il ne peut se concentrer que sur le passé. Il ne voit pas la fenêtre de réponse pendant la génération.
La partie quantile est également cruciale. Le modèle ne dessine pas simplement une ligne future attendue. Il émet un ensemble de quantiles, représentant une distribution de prévisions. Dans ma course, j'ai utilisé neuf niveaux de quantiles, de 0.1 à 0.9.
C'est pourquoi le CRPS est une métrique utile ici. Il récompense un modèle pour sa précision et pour le bon niveau d'incertitude autour de la prévision. Une prévision étroite qui se trompe gravement est pénalisée. Une prévision large qui évite de se tromper en disant très peu est également pénalisée.
Deux types de LLMs pour les séries temporelles
L'expression « LLM pour les séries temporelles » est utilisée pour deux choses différentes.
-
Le premier type est formé nativement sur des données de séries temporelles. Ces modèles transforment des séquences numériques en patches ou tokens, entraînent un transformer sur de nombreux ensembles de données de prévision, et produisent des prévisions directement. t0-alpha, TimesFM, Toto, Chronos, TiRex et Moirai appartiennent largement à ce groupe, bien que leurs architectures diffèrent.
-
Le second type commence avec un LLM textuel pré-entraîné et l'adapte à la prévision. Ces systèmes reprogramment, incitent ou enveloppent un modèle de langage afin qu'il puisse traiter des séquences numériques. Time-LLM est un exemple représentatif de cette direction.
Cet article concerne le premier type.
Où t0-alpha se situe
Tous les chiffres ci-dessous sont des scores normalisés par la moyenne géométrique et par Seasonal-Naive. Plus le score est bas, mieux c'est.
Quelques points se démarquent :
-
t0-alpha surpasse tous les baselines classiques dans ce benchmark. Il bat également deux modèles de fondation strictement plus grands dans ce tableau : timesfm-2.0–500m à environ cinq fois sa taille, et timesfm-1.0 à environ deux fois sa taille. Ces deux modèles plus grands sont signalés pour fuite dans GIFT-Eval.
-
t0-alpha est également situé dans un cluster propre et serré : l'écart de 0.481 à 0.496 est seulement de 0.015 CRPS. Étant donné la variation entre les exécutions, je ne considérerais pas cela comme un classement stable. Ces modèles sont proches.
-
t0-alpha n'est pas le modèle avec la meilleure précision par paramètre ici. TiRex compte seulement 35 millions de paramètres et obtient un score légèrement meilleur. L'écart de précision est suffisamment petit pour que je ne le considère pas comme significatif, mais la différence de taille est réelle.
t0-alpha est un modèle petit, ouvert et reproductible qui se situe dans le cluster compétitif, bien que des modèles propres plus petits puissent l'égaler ou le surpasser.
Où t0-alpha est utile
t0-alpha ne s'effondre que rarement. Sur les 97 tâches, il perd contre Seasonal Naive dans exactement une seule. Dans 96 des 97 configurations, il surpasse la référence standard de répétition saisonnière.
Cette cohérence est importante en pratique. De nombreux systèmes de prévision déployés sont jugés sur la fréquence à laquelle ils produisent des échecs embarrassants lorsqu'ils sont confrontés à une nouvelle série. Le score agrégé de t0-alpha est utile, mais sa large cohérence à travers les tâches est tout aussi pertinente.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.