Tu veux les meilleurs outils IA avant les autres ?
On teste et on décrypte les nouveaux outils IA chaque soir, en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
Introduction
Imaginez une situation où vous demandez à un agent d'intelligence artificielle de comparer les prix de trois concurrents, de compiler ces informations dans un rapport structuré, et de le partager sur un canal Slack avant 9h. En appuyant sur la touche Entrée, trente secondes plus tard, le rapport est prêt et livré. Ce processus, qui semble presque magique, repose en réalité sur une architecture complexe composée de sept couches technologiques distinctes. Chaque couche joue un rôle spécifique et peut rencontrer des problèmes particuliers. Bien que le modèle de base soit souvent sous les feux des projecteurs, les six autres couches sont tout aussi cruciales pour le bon fonctionnement de l'agent.
Selon les prévisions de Gartner, d'ici la fin de 2026, 40 % des applications d'entreprise intégreront des agents d'IA dédiés à des tâches spécifiques, contre moins de 5 % en 2025. Cette adoption rapide ne suit pas une progression linéaire mais plutôt une courbe exponentielle. Pour les ingénieurs et les responsables techniques, il est essentiel de maîtriser l'ensemble de la pile technologique, et pas seulement la couche qu'ils gèrent directement.
Cet article explore chaque couche de cette pile, du modèle de base à l'infrastructure de déploiement. À la fin de cette lecture, vous aurez une compréhension claire de la fonction de chaque couche, de leur interconnexion, et des choix technologiques à envisager à chaque niveau.
Couche 1 : Le modèle de base
Le modèle de base constitue le noyau cognitif de l'agent d'IA. C'est ici que le raisonnement se déroule, que le langage est interprété, et que les décisions sont prises quant aux actions à entreprendre. Les autres couches de la pile fournissent le contexte à ce modèle ou agissent sur ses productions.
En 2026, les principales options pour les modèles de base incluent GPT-5.5 d'OpenAI, Claude Sonnet 4.6 d'Anthropic (ou Claude Opus 4.8 pour des tâches nécessitant un raisonnement plus complexe), Gemini 3.1 Pro de Google, ainsi que des modèles à poids ouverts comme Llama 4 et Mistral Large 3 de Meta. Chaque modèle présente des compromis qu'il est crucial de comprendre avant de faire un choix.
-
GPT-5.5 est reconnu pour sa rapidité et sa fiabilité dans les appels quotidiens, avec un écosystème d'intégrations mature et une vaste communauté de développeurs qui ont déjà résolu de nombreux cas particuliers.
-
Claude Sonnet 4.6 excelle dans la gestion de longs documents et le suivi d'instructions complexes à un coût inférieur à celui de la catégorie Opus d'Anthropic, ce qui est avantageux dans les flux de travail riches en documents. Pour des tâches nécessitant un raisonnement approfondi, Claude Opus 4.8 est recommandé.
-
Gemini 3.1 Pro offre une capacité de traitement de 1 million de tokens, ce qui est essentiel pour les agents devant manipuler de grandes bases de code ou de longues bases de connaissances.
-
Les modèles à poids ouverts comme Llama 4 permettent un contrôle total sur le déploiement et la gestion des données, bien qu'ils nécessitent une infrastructure plus lourde pour fonctionner.
La distinction entre les modèles « standard » et ceux axés sur le raisonnement, qui existait encore en 2025, a disparu. OpenAI, Anthropic et Google ont intégré le raisonnement dans un modèle unique capable de déterminer le temps nécessaire à la réflexion. GPT-5.5 propose des niveaux d'effort de raisonnement ajustables, allant de faible à très élevé, tout comme les paramètres de Claude et les niveaux de réflexion de Gemini. Pour la plupart des tâches d'agents, un réglage par défaut ou à faible effort est suffisant, offrant rapidité et économie. Pour des tâches nécessitant une planification méticuleuse ou un raisonnement mathématique, augmenter le niveau d'effort peut améliorer la précision.
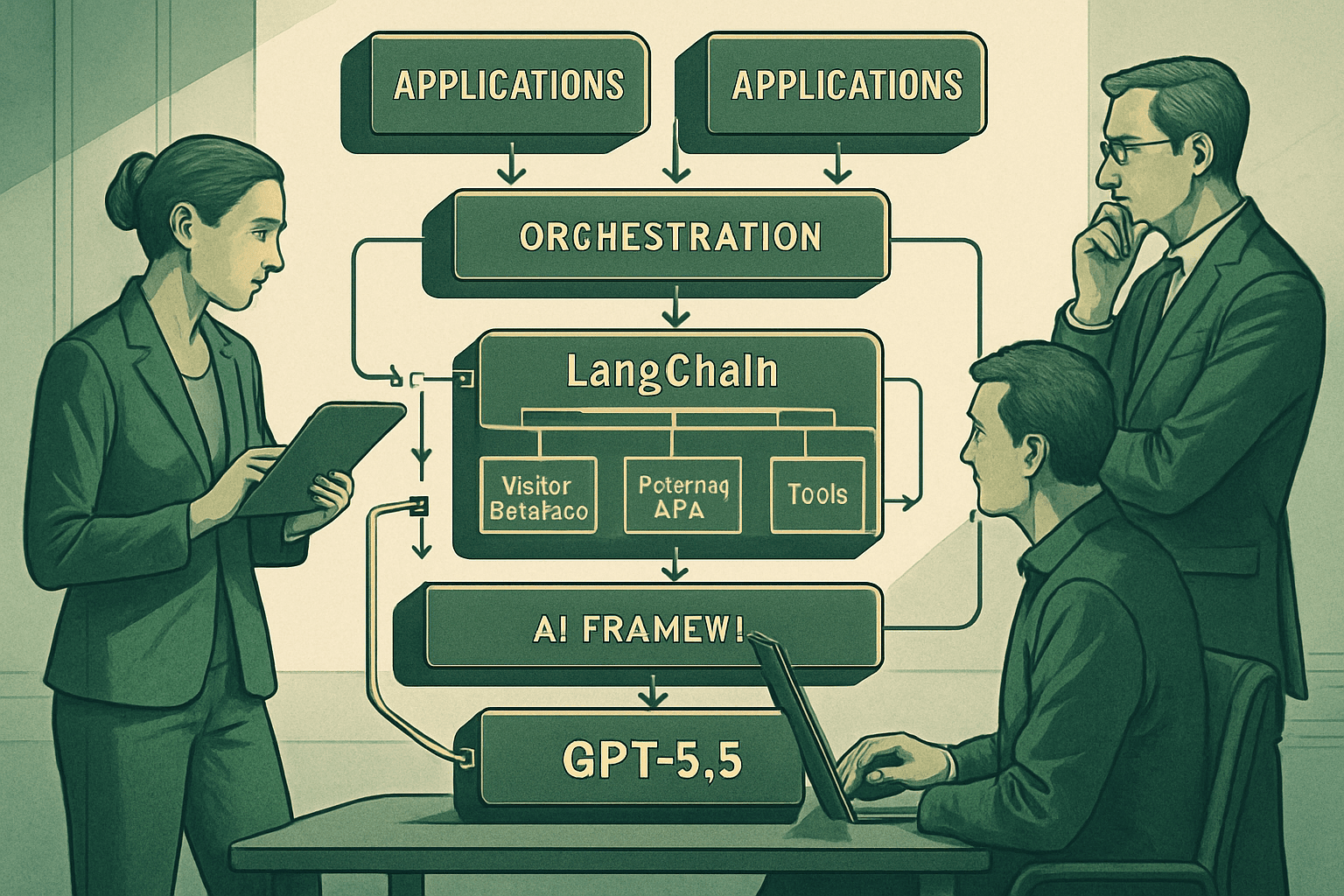
Couche 2 : Le cadre d'orchestration
Si le modèle de base est le cerveau de l'agent, le cadre d'orchestration en est le système nerveux. Il gère le flux de contrôle, déterminant les actions de l'agent, le moment d'appeler un outil, la manière de traiter les résultats, et comment maintenir la cohérence du raisonnement à travers plusieurs étapes.
Le modèle d'orchestration le plus couramment utilisé est appelé ReAct. L'agent génère une pensée, décide d'une action, exécute cette action via un outil, observe le résultat, puis réfléchit à nouveau. Cette boucle se poursuit jusqu'à ce que l'agent produise une réponse finale. Bien que cela semble simple, c'est souvent à ce niveau que se produisent les échecs en production : l'agent peut appeler le mauvais outil, rester bloqué dans une boucle, ou ne pas reconnaître quand il a suffisamment d'informations pour s'arrêter.
LangChain est le cadre le plus largement adopté, offrant un vaste écosystème d'intégrations et une documentation complète. Bien que critiqué pour ajouter trop d'abstraction au stade de prototype, cette critique devient moins pertinente lorsque les fonctionnalités fournies par cette abstraction deviennent nécessaires. LangGraph, développé par la même équipe, est mieux adapté aux flux de travail multi-agents avec état, où un contrôle précis sur le graphe d'exécution est requis. Si votre agent implique plusieurs spécialistes coordonnant une tâche, LangGraph est le choix le plus approprié.
CrewAI est conçu spécifiquement pour la coordination multi-agents. Il permet de définir des agents avec des rôles, de leur assigner des tâches, et de les faire collaborer dans un flux de travail structuré. Il est plus haut niveau que LangGraph et plus rapide à mettre en œuvre, mais offre moins de contrôle sur les détails d'exécution. AutoGen, de Microsoft, adopte une approche conversationnelle des systèmes multi-agents, où les agents interagissent entre eux via une interface de passage de messages, rendant la logique d'interaction très lisible.
Semantic Kernel est l'option axée sur l'entreprise de Microsoft, avec un support prêt pour la production en C#, Python, et Java. Pour les environnements d'entreprise déjà basés sur la pile Microsoft, il s'intègre naturellement. LlamaIndex a commencé comme un cadre d'ingestion et de récupération de documents et a évolué en un cadre d'agent complet, avec un support particulièrement fort pour les flux de travail riches en RAG.
Le choix du cadre dépend des besoins spécifiques de votre agent. Pour un exécuteur de tâches à agent unique, LangGraph ou LangChain sont recommandés. Pour une équipe coordonnée d'agents spécialisés, CrewAI ou AutoGen sont plus adaptés. Pour des environnements d'entreprise, Semantic Kernel est idéal. Pour des flux de travail de récupération riches en documents, LlamaIndex est le choix approprié.
Couche 3 : Systèmes de mémoire
Par défaut, les LLM (modèles de langage de grande taille) sont sans état. Chaque appel commence à zéro, sans connaissance des interactions précédentes, sauf si ce contexte est explicitement passé. Pour une question unique, cette approche est suffisante. Cependant, pour un agent qui doit suivre une conversation, se souvenir des préférences d'un utilisateur, ou s'appuyer sur un travail antérieur, un système de mémoire robuste est indispensable.
