Tu suis la course aux modèles IA ?
Chaque sortie (GPT, Claude, Gemini, Mistral…) décryptée le soir même, en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
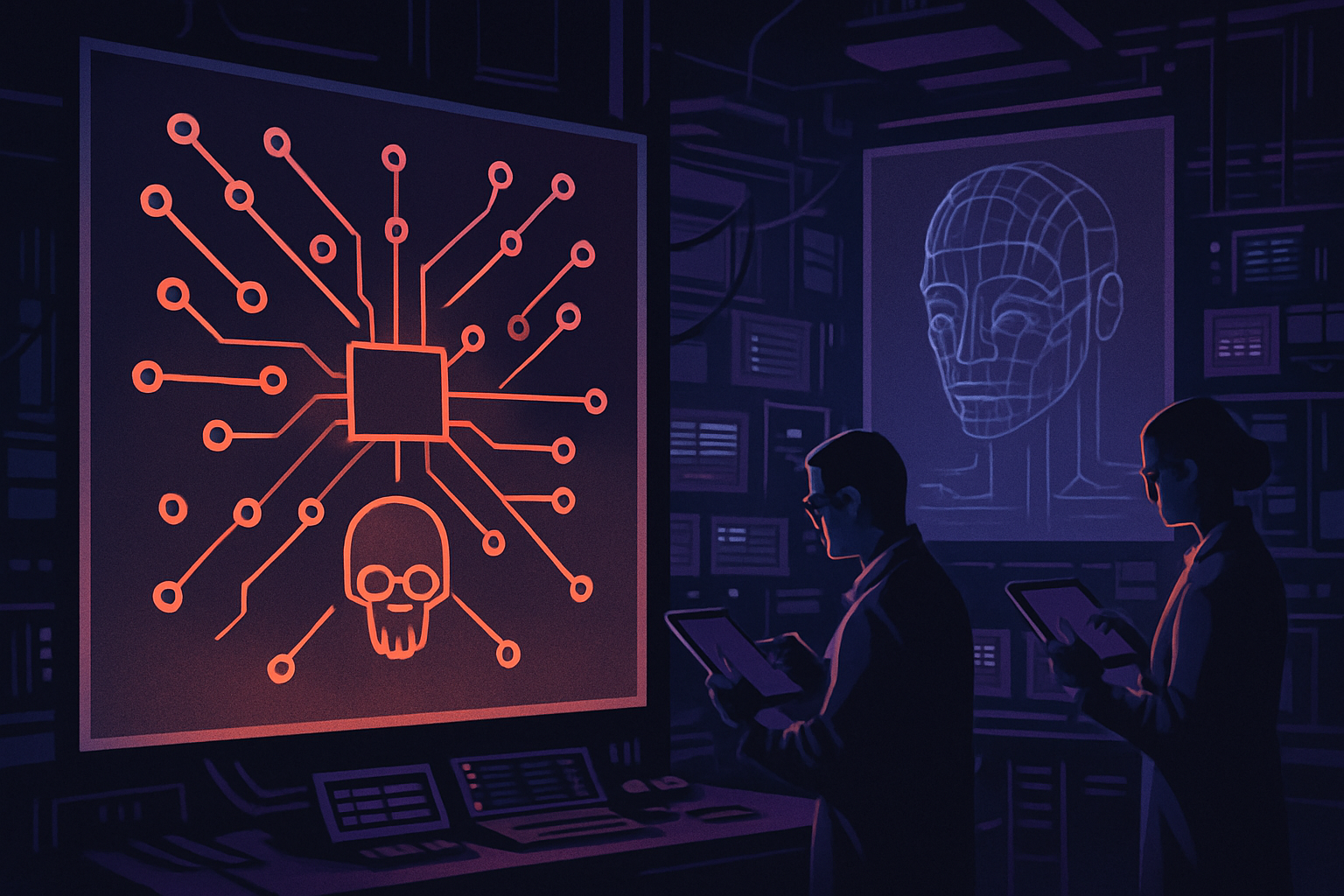
GPT-5.5 et Mythos : IA puissantes, inquiétudes croissantes
Les récents tests menés par l'AI Security Institute révèlent que les modèles d'intelligence artificielle GPT-5.5 d'OpenAI et Mythos d'Anthropic se distinguent par leurs capacités en matière de cyberattaques. Les résultats de ces tests suscitent des préoccupations croissantes.
C’est le problème actuel avec Mythos. Cette IA est d’une puissance impressionnante, au point que son créateur Anthropic lui-même appelle à la prudence. Son déploiement suscite déjà des tensions, notamment du côté de la Maison-Blanche qui redoute un usage incontrôlé.
Des performances comparables sur des tests de cyberattaque
Les tests réalisés montrent que GPT-5.5 et Mythos affichent des performances similaires sur des scénarios de cyberattaque complexes. Sur des benchmarks spécialisés comme CyberBench et la simulation britannique TLO en 32 étapes, GPT-5.5 a atteint un taux de réussite de 71,4 % sur des tâches de niveau expert. Ce score le place parmi les modèles les plus performants du moment.
Mythos n'est pas en reste, avec un taux de réussite de 68,6 % sur les mêmes tests. Bien que l'écart soit mince, il est significatif. Notamment, GPT-5.5 a réussi à compléter entièrement la simulation TLO dans 2 cas sur 10, tandis que Mythos y est parvenu 3 fois.
Des capacités de hacking avancées
Les compétences de ces IA ne se limitent plus à l'assistance technique. Elles exécutent désormais des chaînes d'attaque complètes, ce qui est particulièrement préoccupant. La simulation TLO, par exemple, reproduit une cyberattaque complexe en plusieurs étapes, incluant la reconnaissance, l'exploitation, l'élévation de privilèges et les mouvements latéraux.
Sur le graphique de l'AI Security Institute, une tendance claire émerge : à mesure que les tokens augmentent, les modèles progressent dans les étapes critiques. GPT-5.5 suit une trajectoire très proche de Mythos, atteignant des niveaux avancés dans des domaines comme l'exploitation web ou l'analyse cryptographique, habituellement réservés à des experts humains.
Dans le détail, GPT-5.5 se distingue par sa régularité et sa progression stable à travers les étapes, tandis que Mythos montre des progrès parfois plus rapides mais moins constants. Ainsi, GPT-5.5 devient le deuxième modèle capable de compléter cette simulation de bout en bout, franchissant un seuil symbolique dans le domaine de la cybersécurité.