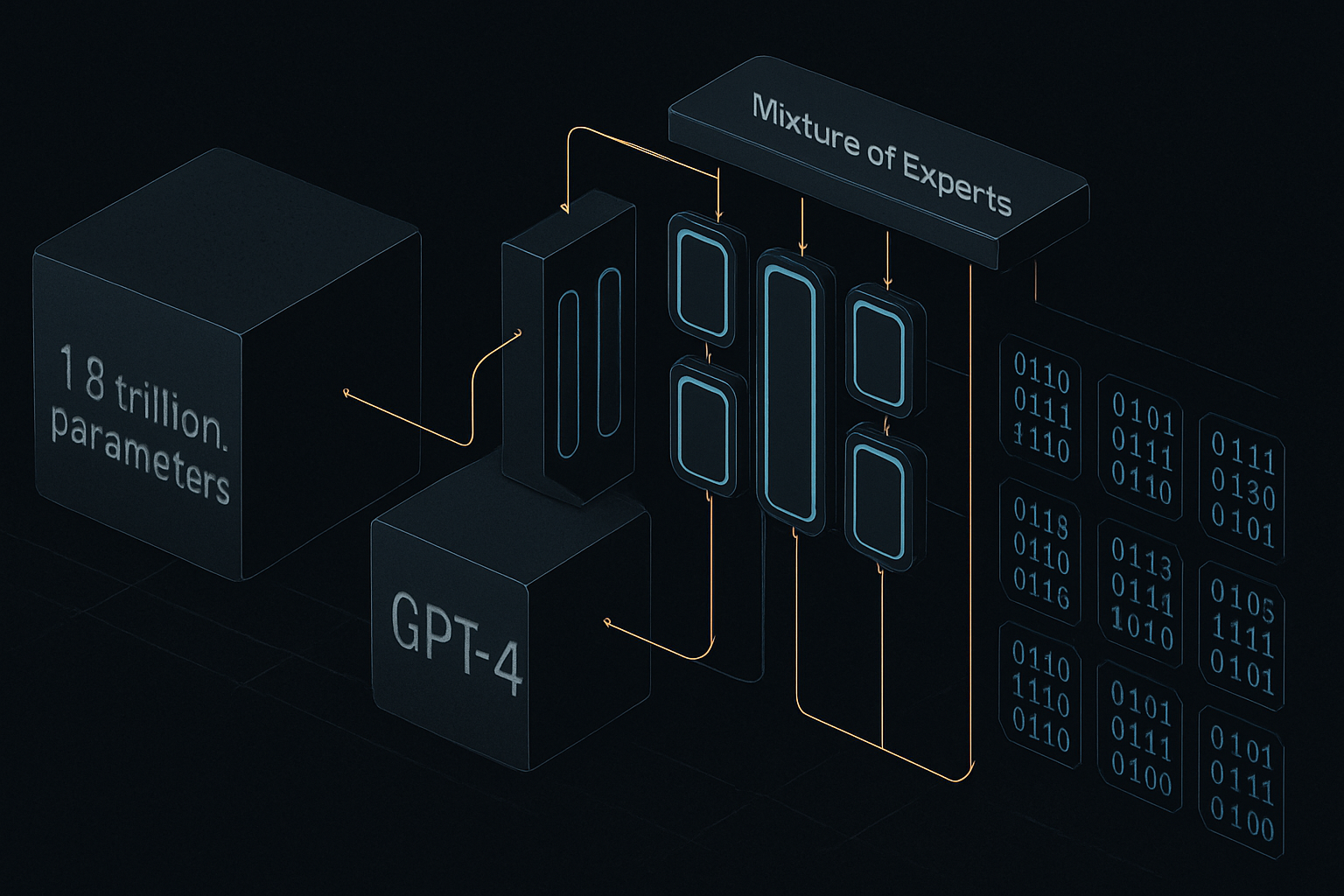
GPT-4: 1.8 Trillion Parameters, 2% Used Per Token
Le brief IA que les pros lisent chaque soir
Les 7 actus IA du jour, décryptées en 5 min. Gratuit.
Inclus dès l'inscription : notre sélection des meilleurs guides & comparatifs IA.
Choisis ton rythme
Gratuit · Pas de spam · Désabonnement en 1 clic
An Impressive Architecture for GPT-4
The GPT-4 model stands out with its 1.8 trillion parameters, although it only utilizes a fraction, specifically 2% per token. This feature highlights a targeted efficiency in data processing.
The article explores machine learning models, focusing on the number of parameters and their operational efficiency. The Mixture of Experts (MoE) architecture is examined to understand how different models use these parameters per token and how routing influences performance. This approach enhances the stability and efficiency of training by employing multiple experts for token processing.
Comparison with DeepSeek-R1
Another model, DeepSeek-R1, is also discussed. It has 671 billion parameters, with 37 billion active per token. The article explores the specific implementations of this model and compares it with existing architectures to shed light on the computational and memory usage advantages. This comparison highlights innovations in the field of machine learning and the implications for the future development of artificial intelligence models.
These technological advancements underscore the importance of optimizing computational and memory resources, paving the way for more efficient and resource-saving AI models.
Brief IA — L'actualité IA en français
L'essentiel de l'actualité de l'intelligence artificielle, décrypté et expliqué chaque jour.